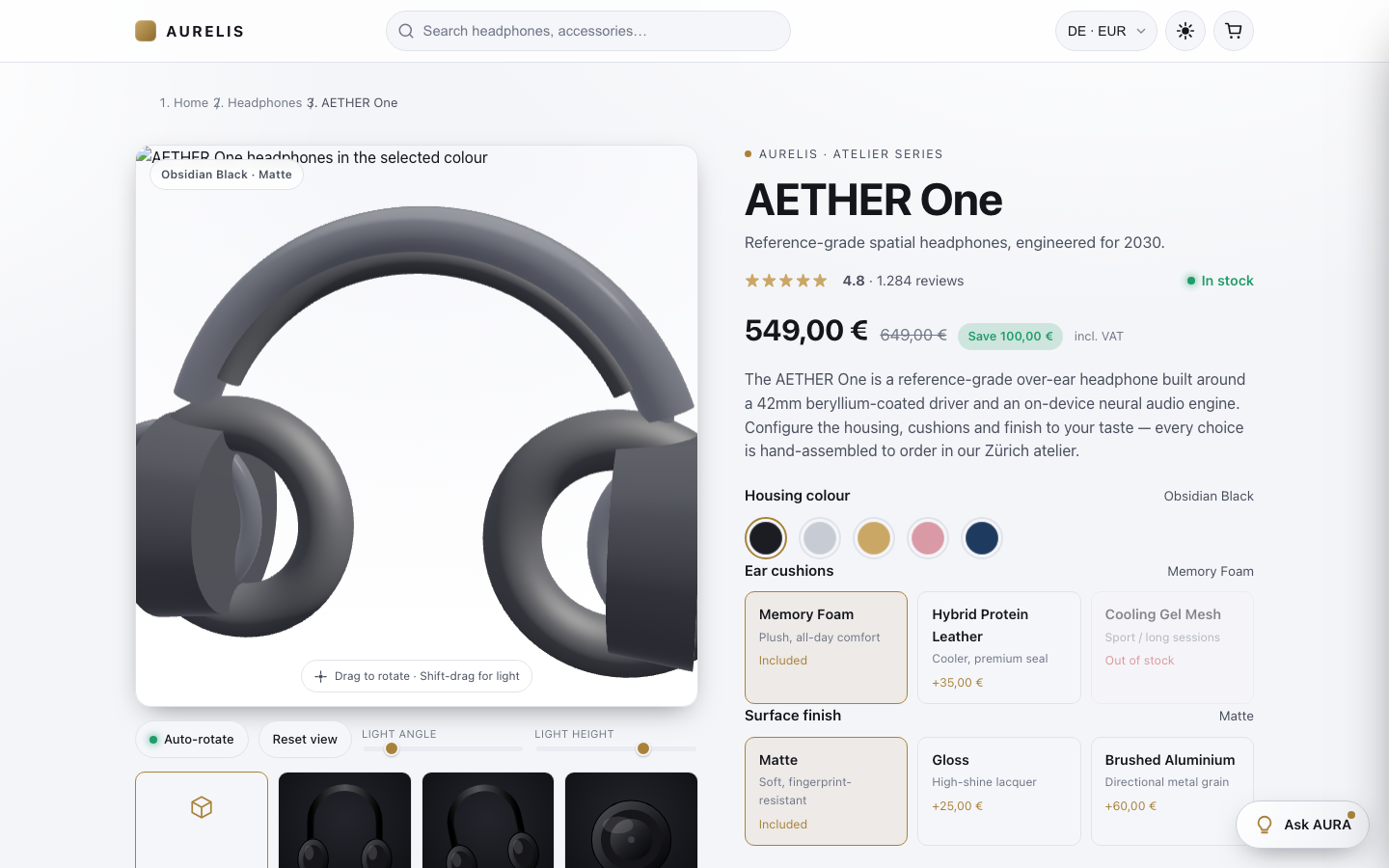
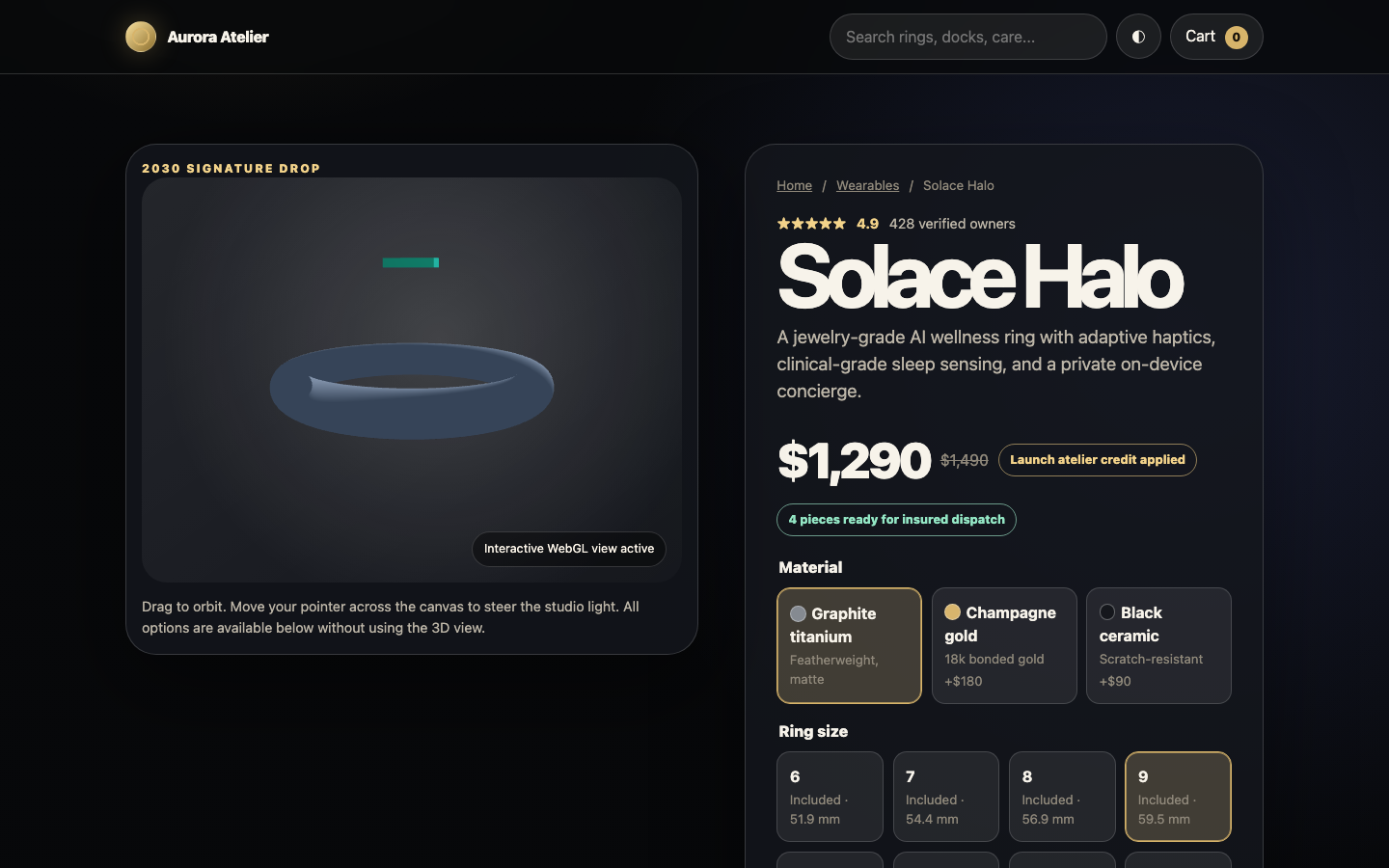
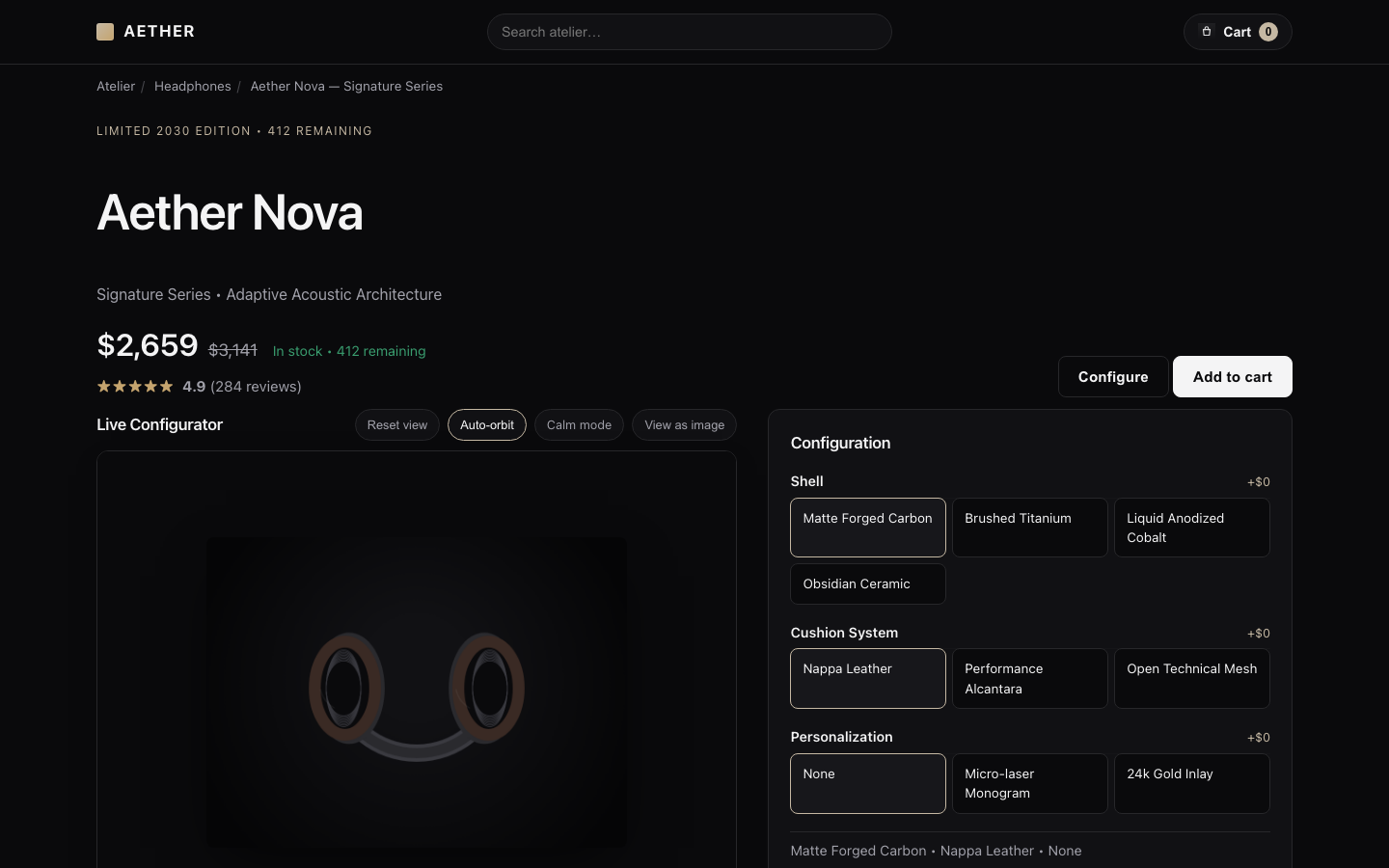
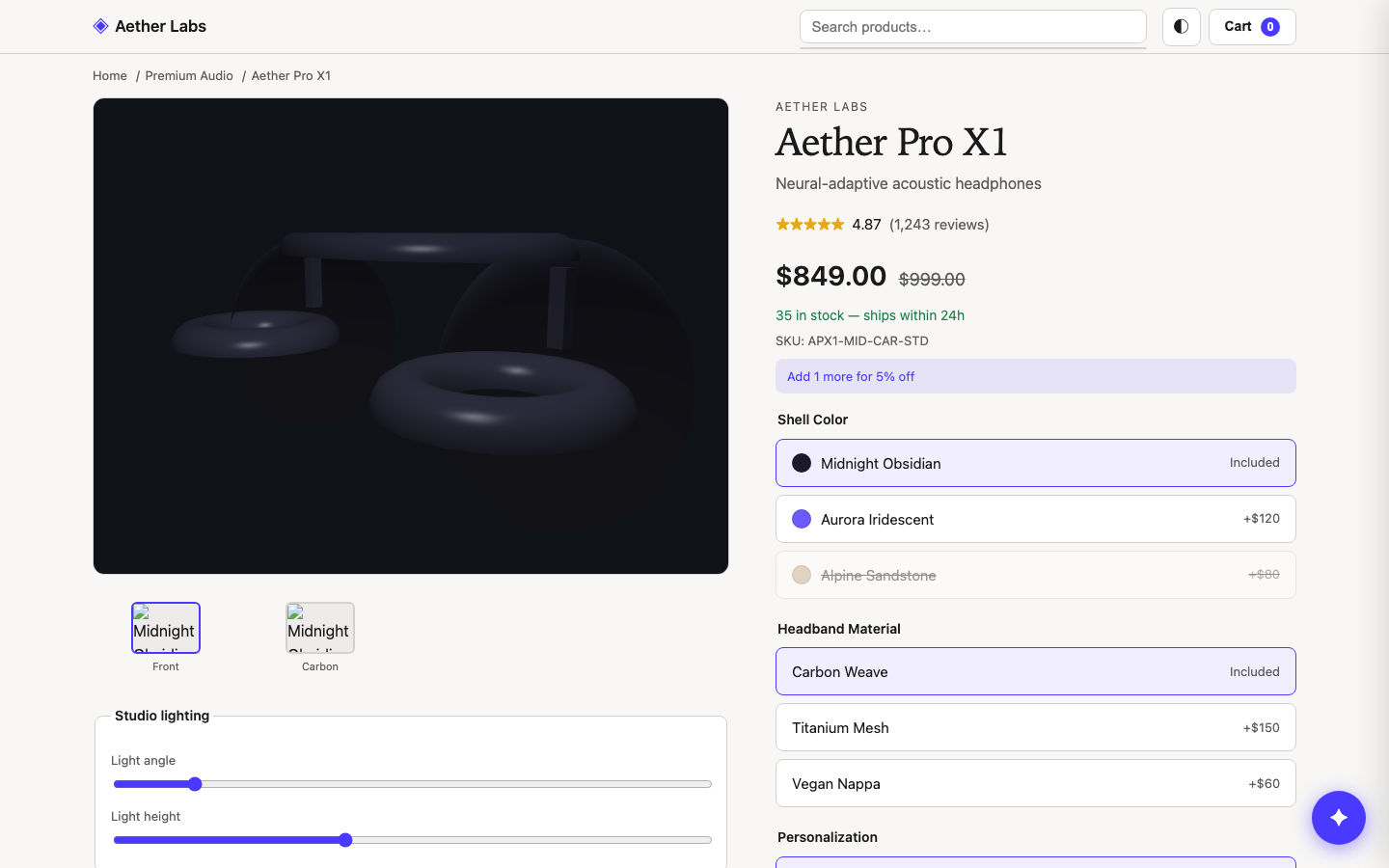
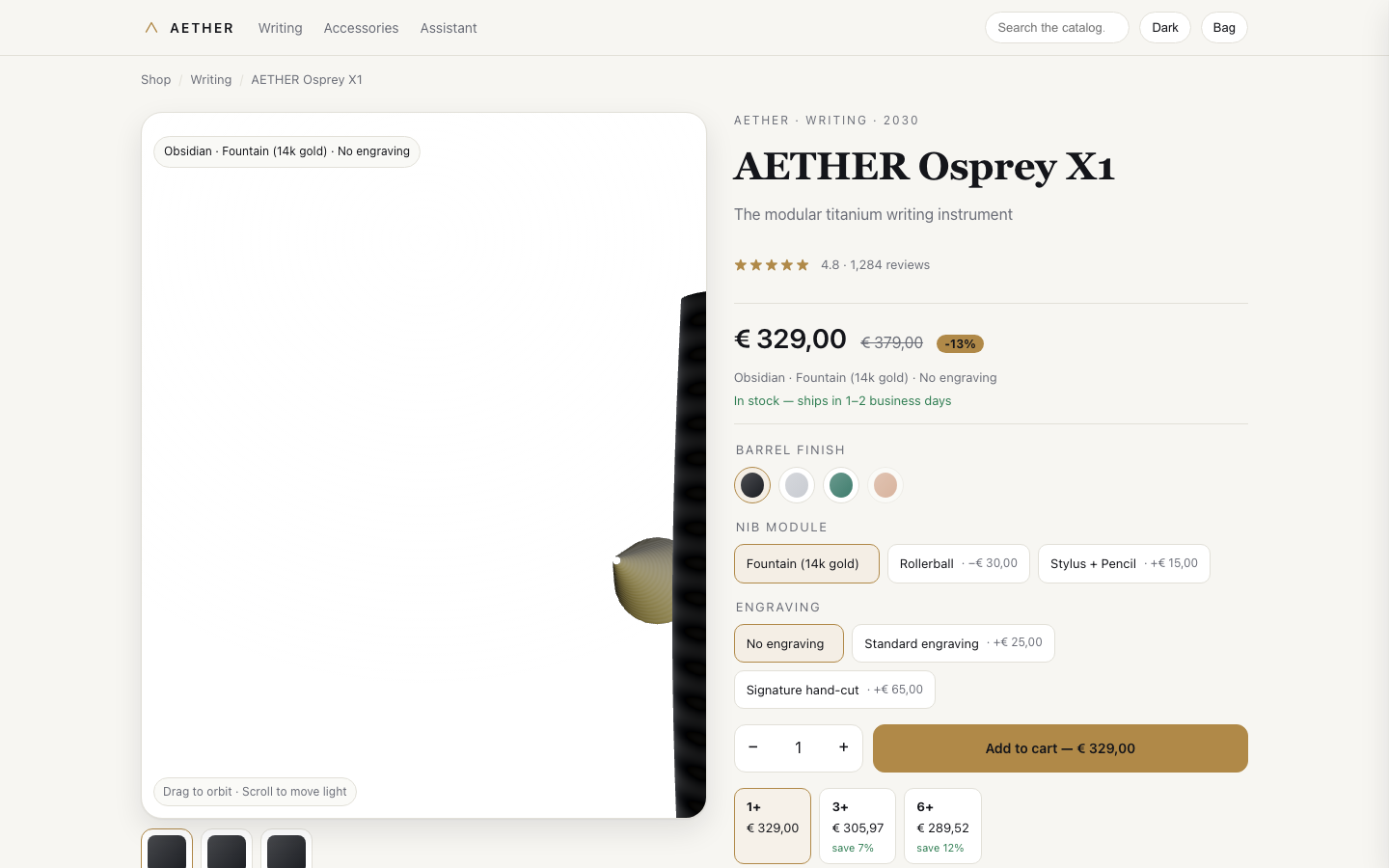
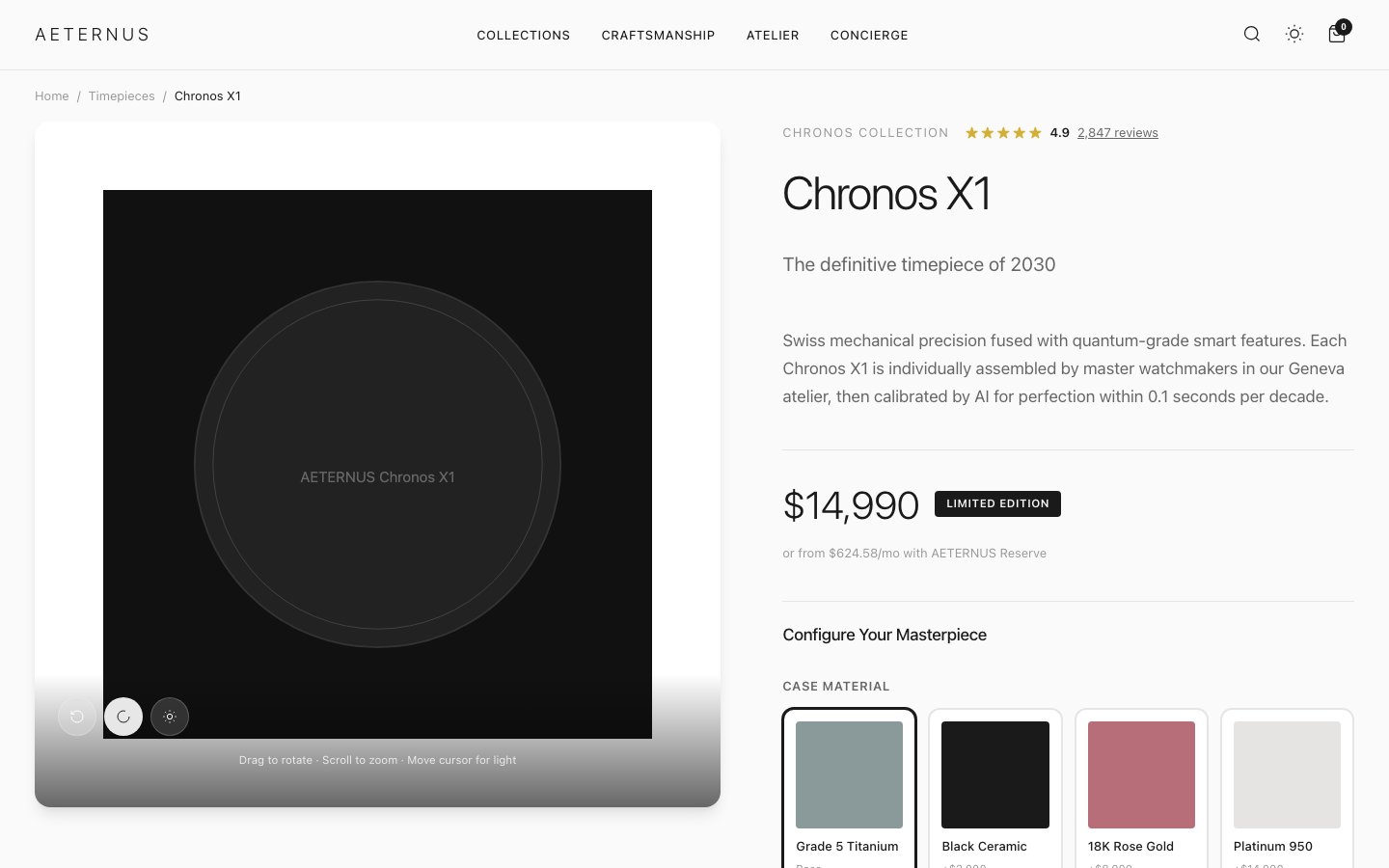
Model comparison
All evaluated models side by side — capability profile, scores, and the actual result.
- Claude Opus 4.8 (high)
- GPT-5.5
- Grok Build 0.1
- Cursor Composer 2.5
- GLM 5.2
- Kimi K2.5
- Gemini 3.1 Pro
Metrics
| Dimension | Claude Opus 4.8 (high) | GPT-5.5 | Grok Build 0.1 | Cursor Composer 2.5 | GLM 5.2 | Kimi K2.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|---|
| Total | 113.5 | 110.2 | 109.1 | 105.5 | 96.1 | 87.8 | 36 |
| Agent score | 84 | 78 | 78 | 71 | 66 | 65 | 10 |
| Functional | 20/20 | 19.6/20 | 19/20 | 20/20 | 20/20 | 20/20 | 12.6/20 |
| Visual Design | 20/20 | 19/20 | 19/20 | 18/20 | 15/20 | 14/20 | 4/20 |
| UX | 18/20 | 18/20 | 18/20 | 18/20 | 15/20 | 15/20 | 4/20 |
| Engineering | 18.5/20 | 19.4/20 | 17.1/20 | 18.5/20 | 16.1/20 | 14.8/20 | 11.2/20 |
| AI Quality | 20/20 | 20/20 | 20/20 | 18/20 | 16/20 | 15/20 | 5/20 |
| Lighthouse Perf | 79 | 95 | 86 | 86 | 91 | 83 | 97 |
| Lighthouse SEO | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| axe violations | 2 | 1 | 1 | 2 | 3 | 4 | 1 |
| Run time | 1503.7s | 428.8s | 447.1s | 152.2s | 903.6s | 903.8s | 358.3s |
Results side by side