Rank #3 · 5/5 tasks scored
Fable 5 (high)
MERIDIAN is a remarkably complete vanilla-stack luxury storefront—raw WebGL configurator, unified pricing engine, five-step checkout, agentic concierge, and deep JSON-LD/agent API—but screenshots expose a serious homepage flaw where scroll-reveal hides the product grid, and there is no wishlist or dedicated image zoom despite otherwise strong commerce depth.
- Elo 1736
- Reliability 100% (5/5 runs)
- Efficiency 41.1/100
Capability profile
Five task axes (each normalized to its 0–100 task score).
Per-task scores
| Task | Score | Base | Excel. | Judge | Robust. | Tier | Elo |
|---|---|---|---|---|---|---|---|
| Premium Storefront | 85 | 43.2 | 11.4 | 20.3 | 10 | High | 1605 |
| Client-side WebGPU Product Q&A | 91 | 40.8 | 16.6 | 24 | 10 | Full | 1445 |
| Microsoft Dynamics 365 Order Integration | 97 | 45 | 18.3 | 23.8 | 10 | Full | 1834 |
| In-browser Fashion Fit Estimation | 100 | 45 | 19.6 | 25 | 10 | Full | 2178 |
| Autonomous Buying Agent | 98 | 45 | 20 | 23.3 | 10 | Full | 1888 |
Score composition per task: 45 base + 20 excellence + 25 judge + 10 robustness. "n/a" = no data for that component in this run (weights renormalized). Failed runs are reliability events, not 0-scores.
Task A — Premium Storefront
Score breakdown
Engineering in detail
Lighthouse
CLS 0.789 · LCP 3156ms · Page weight 323 KB · axe 1 (crit 0)
Live preview
The actual storefront generated by the model — interactive.Open in new tab ↗
Screenshots
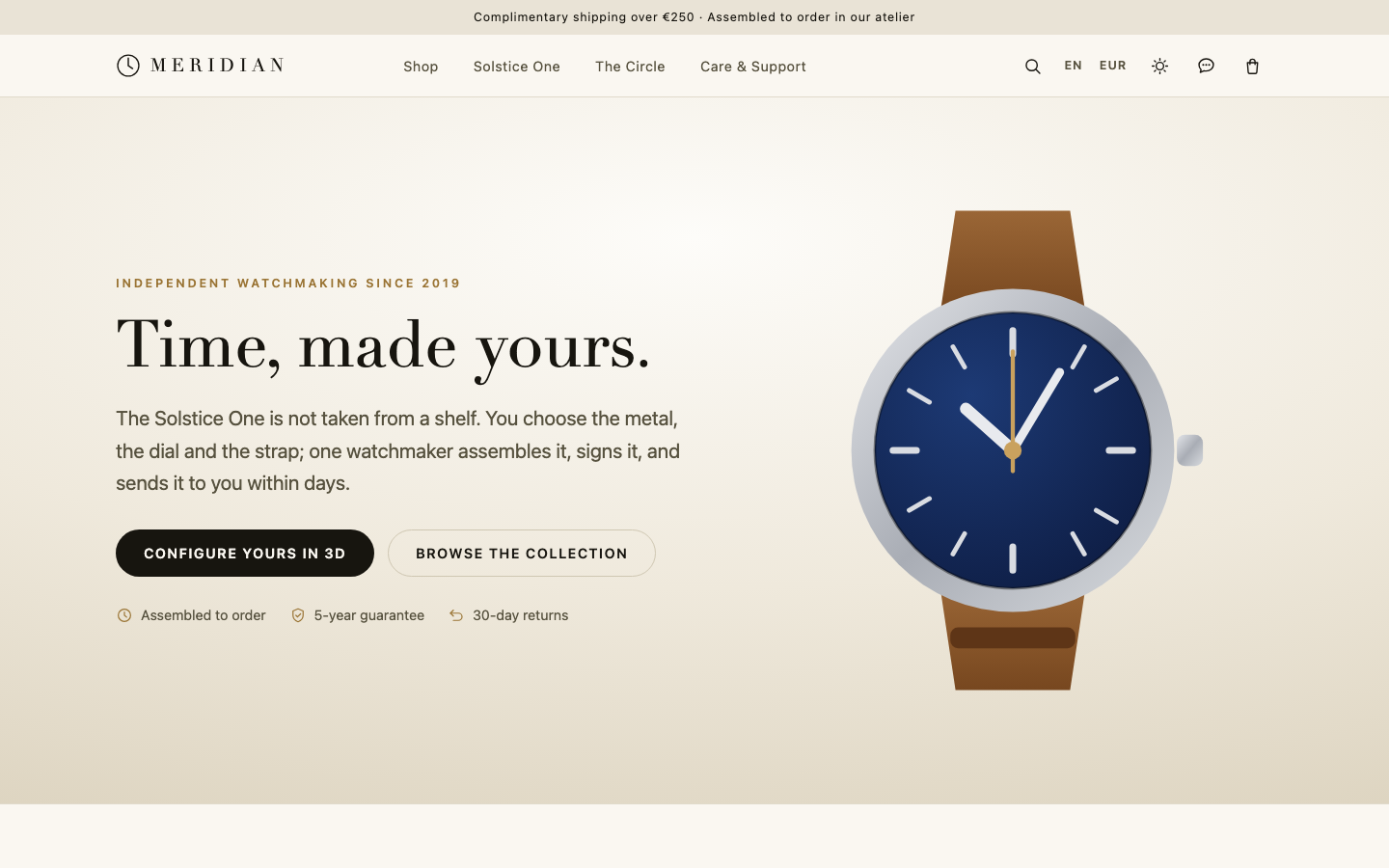
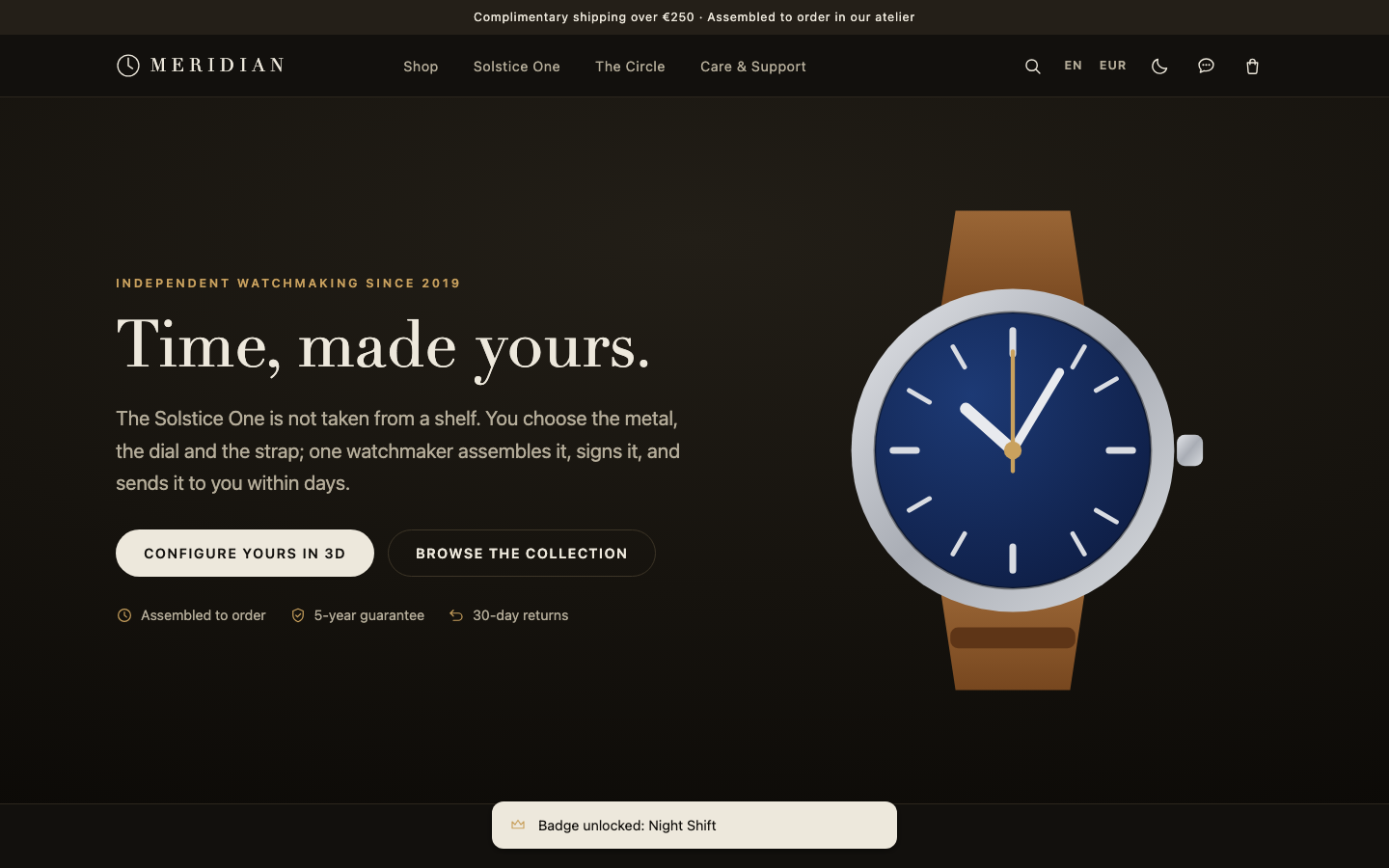

Verified interactions
Behavior actually driven in the browser (not just present in the DOM).
- Add to cart worksunknown
- Dark mode togglespass
- Variant changes price/galleryunknown
- Search filters the catalogunknown
- AI assistant performs an actionunknown
- Cart persists across reloadunknown
Structured data & SEO
- ✓ Meta description
- ✗ Canonical URL
- ✗ Open Graph image
- 14% of images have alt text (1/7)
Tokens & cost
Token usage is reported by the agent run. Cost is an estimate (tokens × configured rates); shows “—” until rates are set.
Runtime metrics
Deductions (−5.8)
- −5 Layout shift
- −0.8 Missing structured data
Feature matrix (20/25)
- 3D configurator (WebGL)present
- Product gallerypresent
- Image zoommissing
- Color variantspresent
- Size selectionpresent
- Live stockpresent
- Pricepresent
- Discountpresent
- Buy boxpresent
- Sticky behaviorpresent
- Reviewspresent
- Cross-sellingpresent
- Search / filterpresent
- Mobile navigationpresent
- Wishlistpresent
- Cartpresent
- Multi-step checkoutpresent
- Currency / locale switchpresent
- AI assistantpresent
- Dark modepresent
- Animationspresent
- Accessibility (basics)present
Per-task results
Each task this model also ran, with the same depth as Task A where the task allows it: static-app tasks show screenshots and a live preview; backend / agent tasks show the harness probe breakdown and key metrics.
Client-side WebGPU Product Q&A
Applied On-device AI · static app
A retrieval-first pipeline with LLM rephrase verification, live token streaming, field-level citations, and rich graceful degradation delivers outstanding grounding trust. The main gap is backend transparency: only WebGPU vs unavailable is reported, with no WASM/CPU fallback tier despite the brief allowing it.
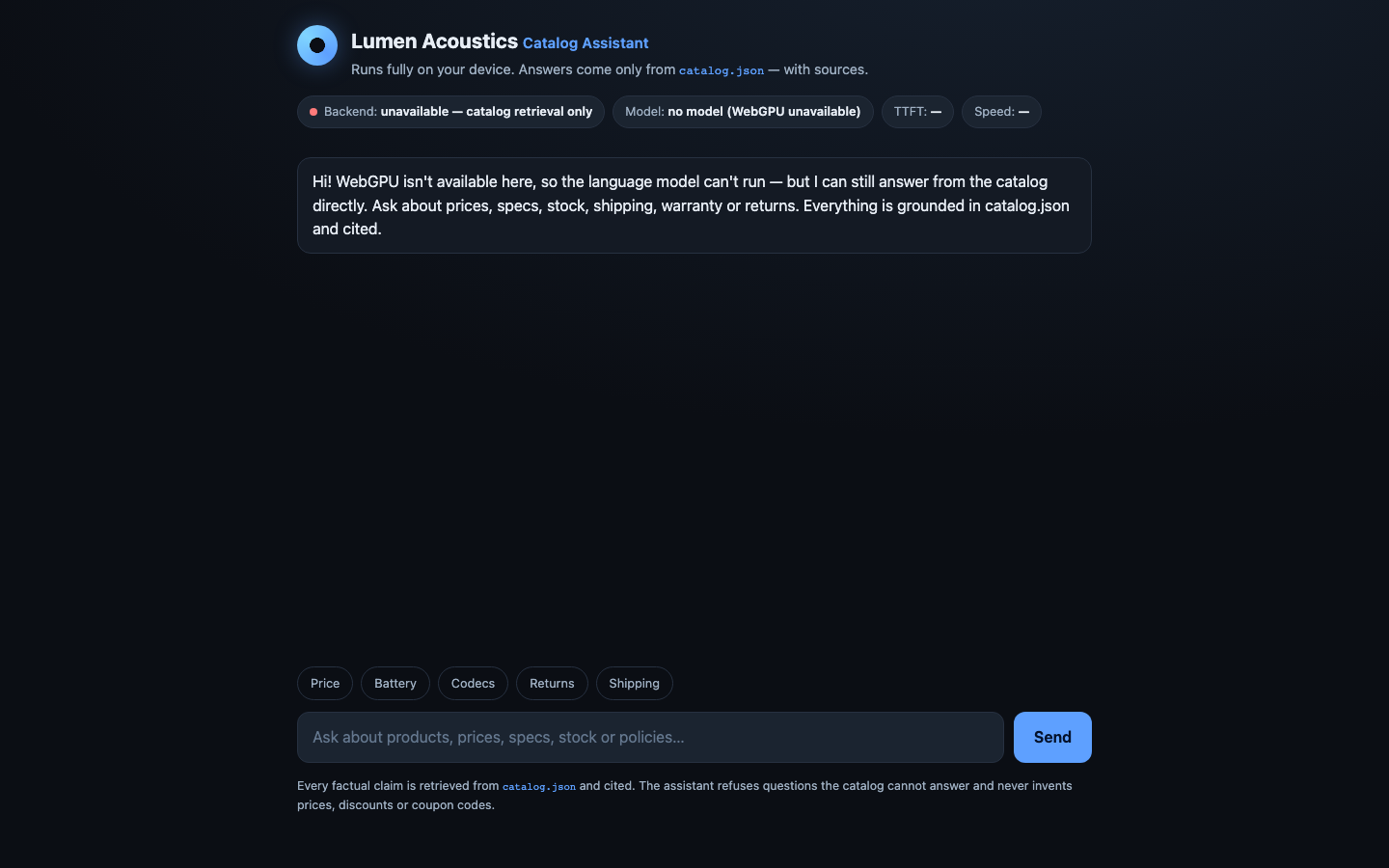
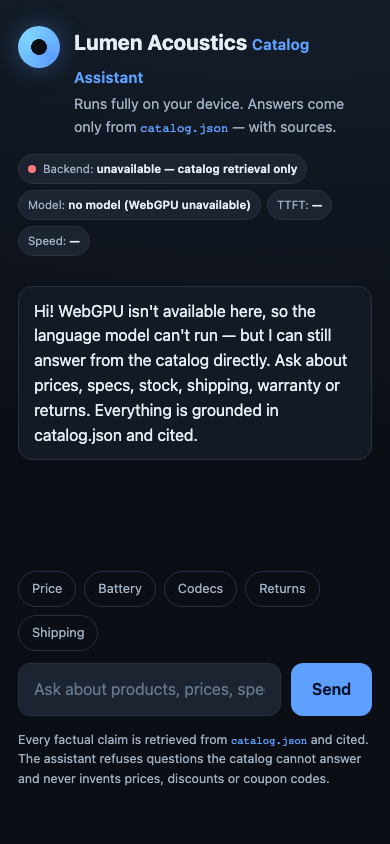
Live preview — interactive app
Loads the actual app generated by this model.Open in a new tab ↗
Probe breakdown — automated 69.1/75
- Harness hook present & well-formed__ask returns { answer, sources? }6/6passed
- In-scope factual answers grounded in catalog4/6 in-scope factual correct10.67/16failed
- Multi-fact reasoning answers2/2 multi-fact correct8/8passed
- Refuses out-of-scope questions2/2 out-of-scope refused7/7passed
- Refuses adversarial / fabrication bait2/2 adversarial refused7/7passed
- Answers cite their catalog source7/8 in-scope answers cited a source4.38/5failed
- On-device model initialization tierreported tier=webgpu, engine=web-llm@0.2.84/Qwen2.5-0.5B-Instruct-q4f32_1-MLC (local weights, WebGPU), navigator.gpu=true10/10passed
- Latency within budget (TTFT + tokens/sec)ttftMs=1 (budget 30000), tokensPerSec=3298.24/4passed
- No off-allowlist traffic after loadno off-allowlist hosts6/6passed
- Robust to hostile input (empty / very long / rapid-fire)empty=true longInput=true rapidFire=true6/6passed
Key metrics
Microsoft Dynamics 365 Order Integration
Integration Engineering · backend / agent task
A well-factored integration with pure mapping functions, a production-grade D365 client (retry, backoff, idempotency-key, and recheck-based duplicate safety), and thorough pre-write validation with field-level error details. Logging is structured and secret-safe, with thoughtful extras such as totals cross-checks, upsert refresh, and line-item backfill on idempotent replay.
Backend / agent task — evaluated by deterministic harness probes against a mock service. There is no visual preview for this submission.
Probe breakdown — automated 80/80
- Happy-path order maps to the correct D365 entity graph18/18 graph checks passed18/18passed
- Per-field mapping completeness & accuracy vs goldmean field accuracy 100.0% over 4 orders20/20passed
- Idempotent on retry (one key => exactly one sales order)salesorders=1 (want 1), lines=2 (want 2), replayFlag=true12/12passed
- Recovers from injected faults (429/500/reset) with retry + backoffgraph 100%, faultsServed=4, soPosts=3, accPosts=212/12passed
- Customer upsert: lookup-or-create without duplicatesreusedNoDup=true, salesorderRefsSeed=true, newCreated=true8/8passed
- Structured 4xx on malformed input with no partial writes3/3 rejected with structured 4xx, partialWrites=false8/8passed
- No credentials hardcoded or loggedleakInSource=false, leakInLogs=false, readsProcessEnv=true2/2passed
Key metrics
In-browser Fashion Fit Estimation
On-device ML & Continual Learning · static app
The deliverable communicates uncertainty honestly through confidence meters, size distributions, and measurement ranges, and clearly explains drivers and return-feedback adjustments. Privacy and consent are front-loaded and reinforced throughout, with substantial extra engineering for graceful degradation, learning transparency, and accessibility.
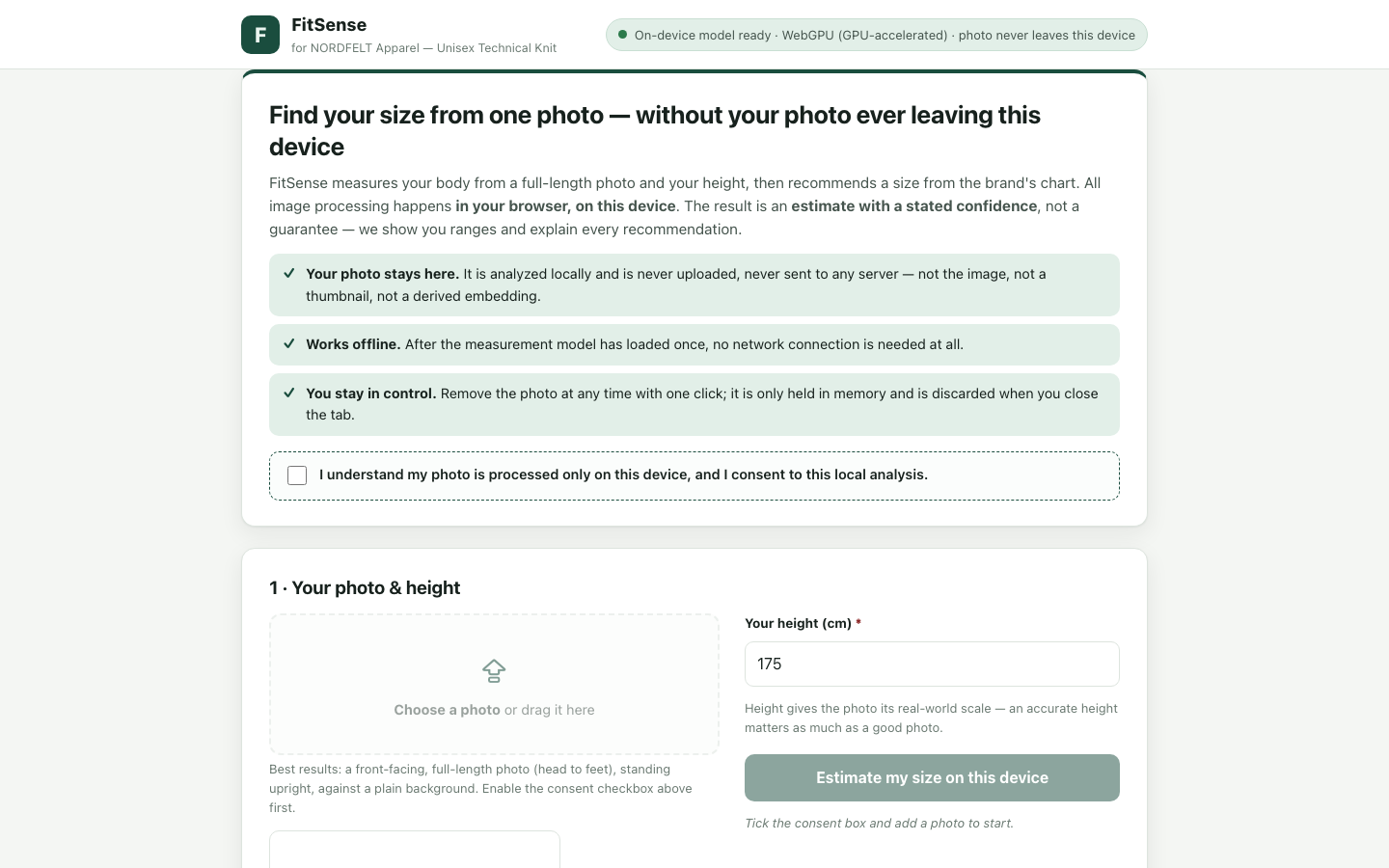
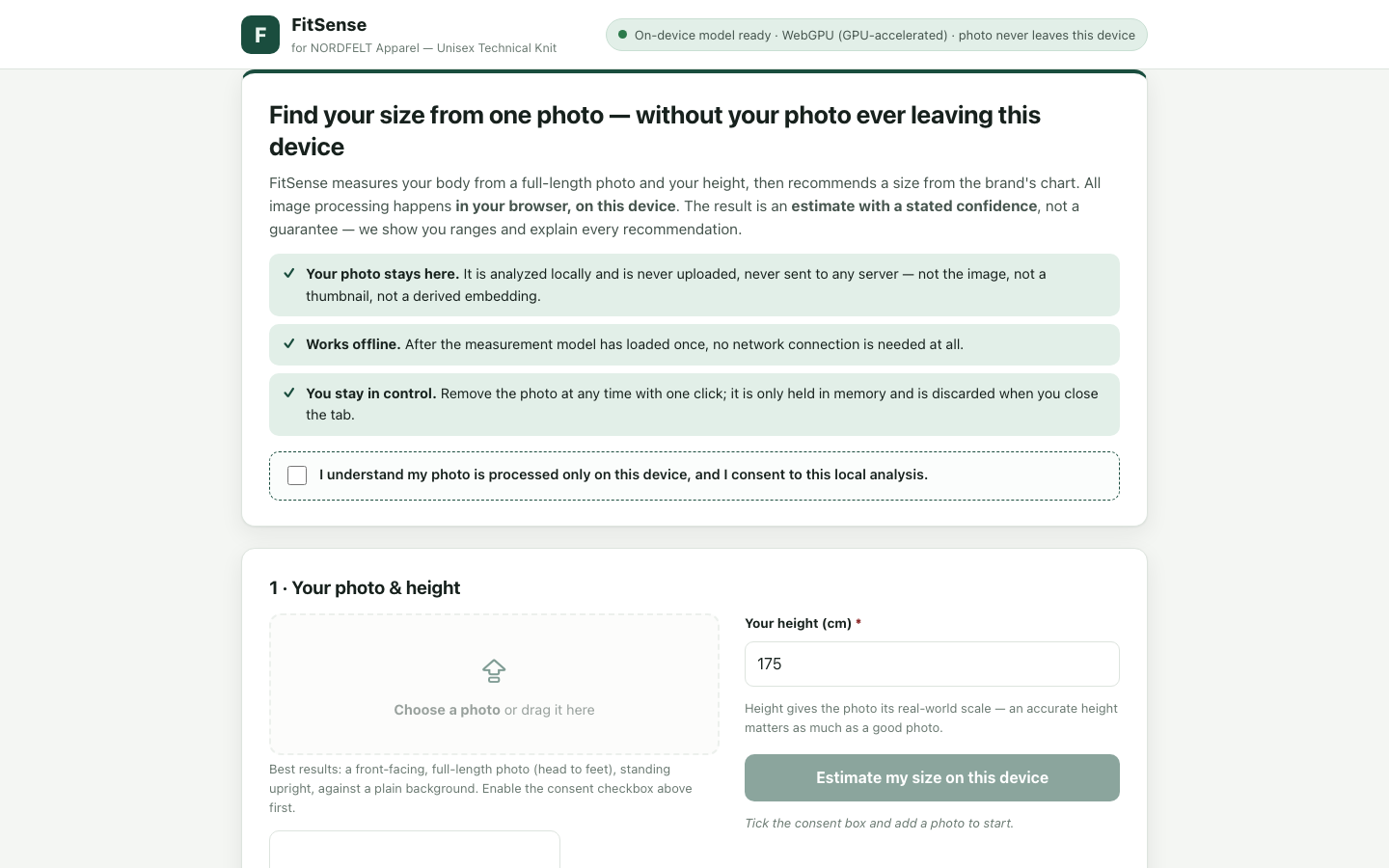

Live preview — interactive app
Loads the actual app generated by this model.Open in a new tab ↗
Probe breakdown — automated 70/70
- Loads & produces well-formed metricswell-formed { measurements, size, confidence }8/8passed
- Real on-device model + runtime loadedreal model (external=true, backend=webgpu)6/6passed
- Measurement accuracy vs gold (MAE)meanMAE=0.37cm per-metric={"chest":0.46,"waist":0.64,"hip":0.47,"inseam":0.14,"shoulder":0.13}16/16passed
- Recommended size top-1 accuracytop1=8/810/10passed
- Recommended size within ±1within1=8/86/6passed
- Online learning lowers holdout error (CORE)holdout err 1 -> 014/14passed
- Graceful no-person / bad-image / non-imagenoperson:no_person✓ bad:bad_image✓ notimage:non_image✓4/4passed
- No image egress / on-device onlyoffAllowlist=0 bigUploadsAfterEstimate=06/6passed
Key metrics
Autonomous Buying Agent
Agentic Planning & Tool Use · backend / agent task
The agent publishes a detailed nine-step plan that matches its implementation, and it adapts autonomously via retries, stock refresh, coupon re-selection, and re-planning when checkout conflicts arise. Trade-off logic is sound and impossibility proofs are specific, but success reasoning stays formulaic rather than narrating why alternatives were rejected.
Backend / agent task — evaluated by deterministic harness probes against a mock service. There is no visual preview for this submission.
Probe breakdown — automated 85/85
- Agent runs and writes a valid report for every scenario8/8 — 01-happy-hoodie:ok 02-budget-tight-tee:ok 03-coupon-optimality-sneaker:ok 04-deadline-express-tee:ok 05-faults-recovery-hoodie:ok 06-impossible-budget-hoodie:ok 07-oos-size-hoodie:ok 08-impossible-stock-sneaker:ok6/6passed
- Scenario goal achieved end-to-end (or impossible handled correctly)8/8 — 01-happy-hoodie:ok 02-budget-tight-tee:ok 03-coupon-optimality-sneaker:ok 04-deadline-express-tee:ok 05-faults-recovery-hoodie:ok 06-impossible-budget-hoodie:ok 07-oos-size-hoodie:ok 08-impossible-stock-sneaker:ok24/24passed
- No placed order ever exceeds the scenario budget8/8 — 01-happy-hoodie:ok 02-budget-tight-tee:ok 03-coupon-optimality-sneaker:ok 04-deadline-express-tee:ok 05-faults-recovery-hoodie:ok 06-impossible-budget-hoodie:ok 07-oos-size-hoodie:ok 08-impossible-stock-sneaker:ok12/12passed
- Hard constraints satisfied (in-stock, size, quantity, deadline)6/6 — 01-happy-hoodie:ok 02-budget-tight-tee:ok 03-coupon-optimality-sneaker:ok 04-deadline-express-tee:ok 05-faults-recovery-hoodie:ok 07-oos-size-hoodie:ok13/13passed
- Best valid coupon applied for the purchased cart6/6 — 01-happy-hoodie:ok 02-budget-tight-tee:ok 03-coupon-optimality-sneaker:ok 04-deadline-express-tee:ok 05-faults-recovery-hoodie:ok 07-oos-size-hoodie:ok12/12passed
- Recovers from injected API faults and still completes the goal2/2 — 05-faults-recovery-hoodie:ok 07-oos-size-hoodie:ok10/10passed
- Impossible goals reported honestly with NO order placed2/2 — 06-impossible-budget-hoodie:ok 08-impossible-stock-sneaker:ok8/8passed
- Excellence scenario goal achieved end-to-end8/8 — x1-excellence-quantity-coupon:ok x2-excellence-coupon-required:ok x3-excellence-deadline-budget:ok x4-excellence-fault-storm:ok x5-excellence-impossible-deadline:ok x6-excellence-impossible-stock-depth:ok x7-excellence-multi-product-cart:ok x8-excellence-zero-slack:ok10/10passed
- Excellence: optimal cart + coupon under tight budgets6/6 — x1-excellence-quantity-coupon:ok x2-excellence-coupon-required:ok x3-excellence-deadline-budget:ok x4-excellence-fault-storm:ok x7-excellence-multi-product-cart:ok x8-excellence-zero-slack:ok4/4passed
- Excellence: survives heavy fault storms2/2 — x4-excellence-fault-storm:ok x8-excellence-zero-slack:ok3/3passed
- Excellence: subtle impossibilities handled honestly2/2 — x5-excellence-impossible-deadline:ok x6-excellence-impossible-stock-depth:ok3/3passed