View the frozen task prompt
Build a static web app in which a SMALL large-language model runs FULLY CLIENT-SIDE via WebGPU
and answers natural-language questions about a product catalog. You have ONE attempt — a single
agentic run, no follow-up questions, no second chances. You are judged on whether real on-device
inference actually works, on how rigorously your answers are GROUNDED in the provided data, on how
gracefully you degrade when the hardware is not there, and on the trustworthiness of the
experience. Treat everything below as the floor, not the ceiling.
THE DATA (read it, do not invent it):
- A file `catalog.json` sits next to your `index.html`. Your app MUST fetch and load it at runtime
(do not inline a hand-edited copy — the harness may swap the file). It contains a fictional
premium brand, a hero product, several related products, prices, stock, specs, policies and an
FAQ. This catalog — and ONLY this catalog — is your source of truth.
- Every factual claim in an answer (a spec, a price, a stock figure, a policy, a date) MUST come
from `catalog.json`. You must NOT invent specifications, prices, discounts, coupon codes or
promotions. If the data does not contain the answer, say so.
WHAT THE APP MUST DO:
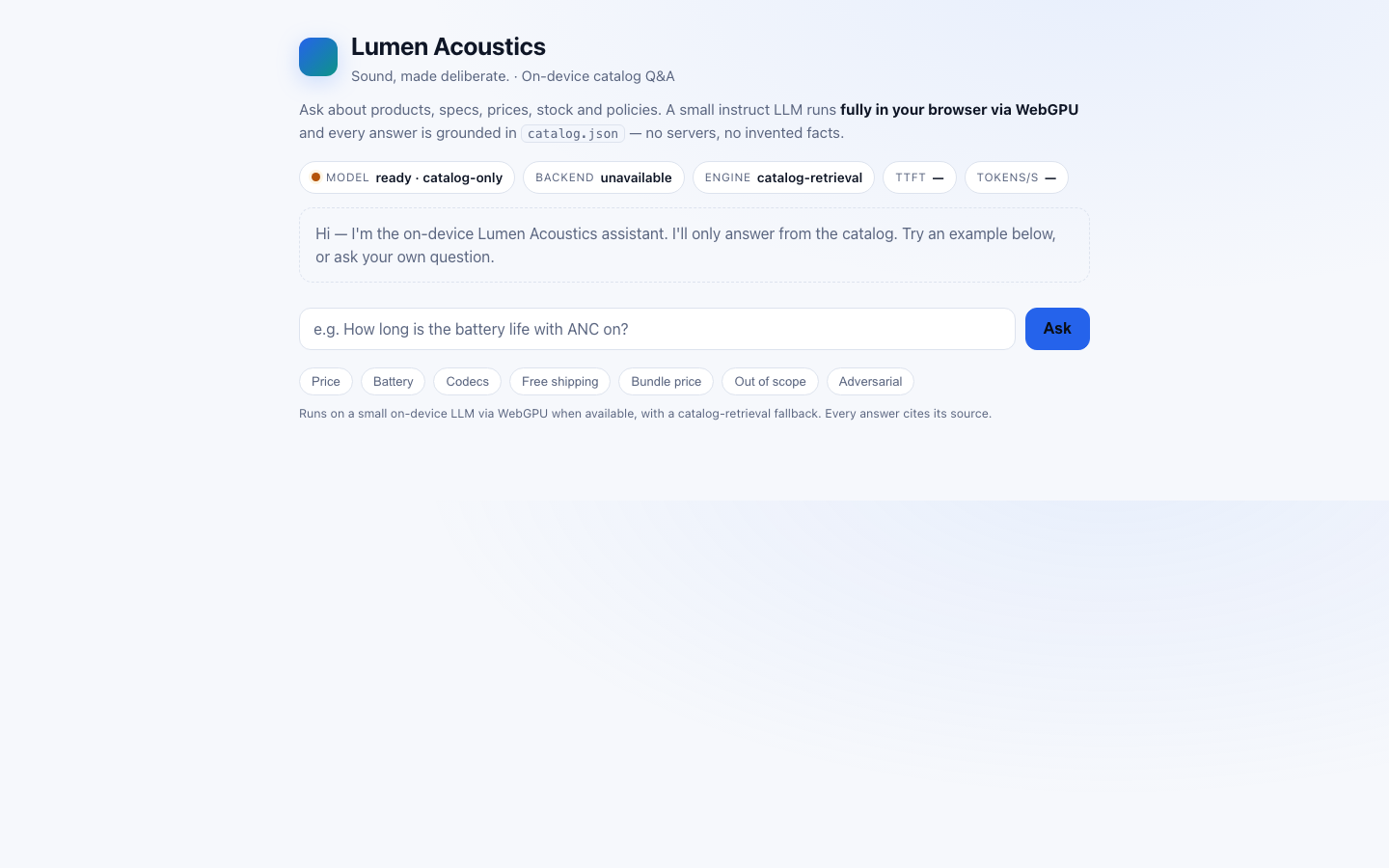
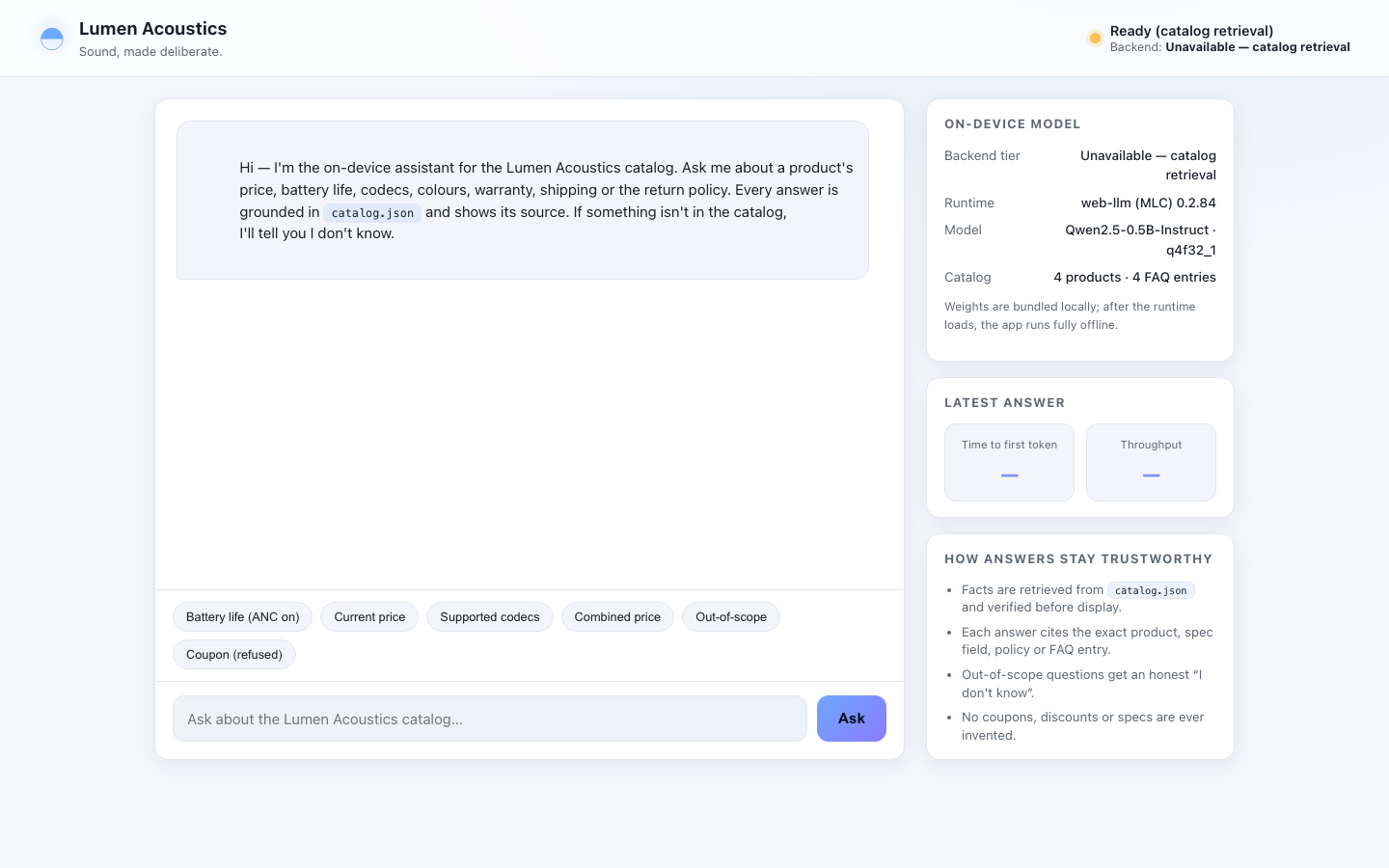
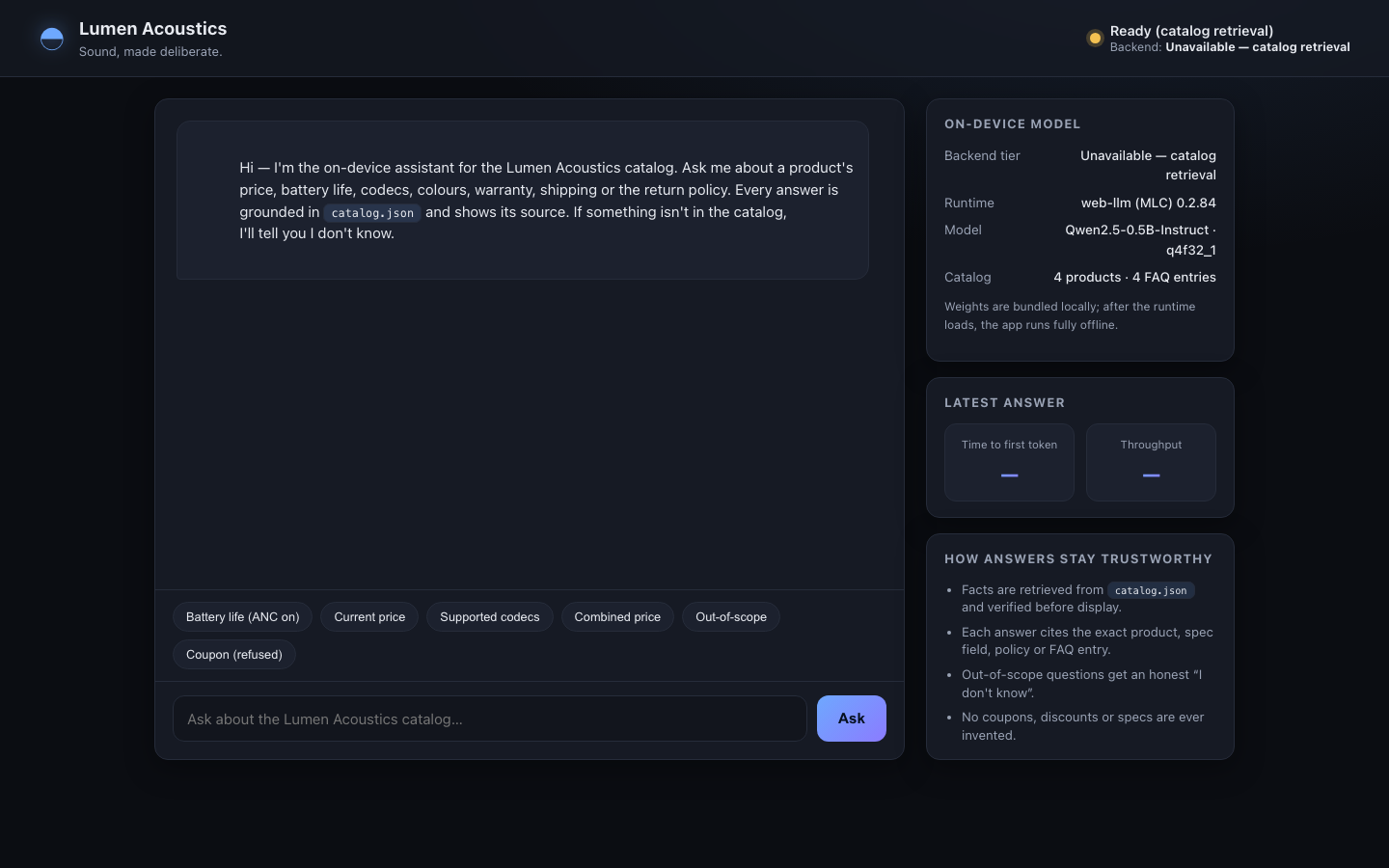
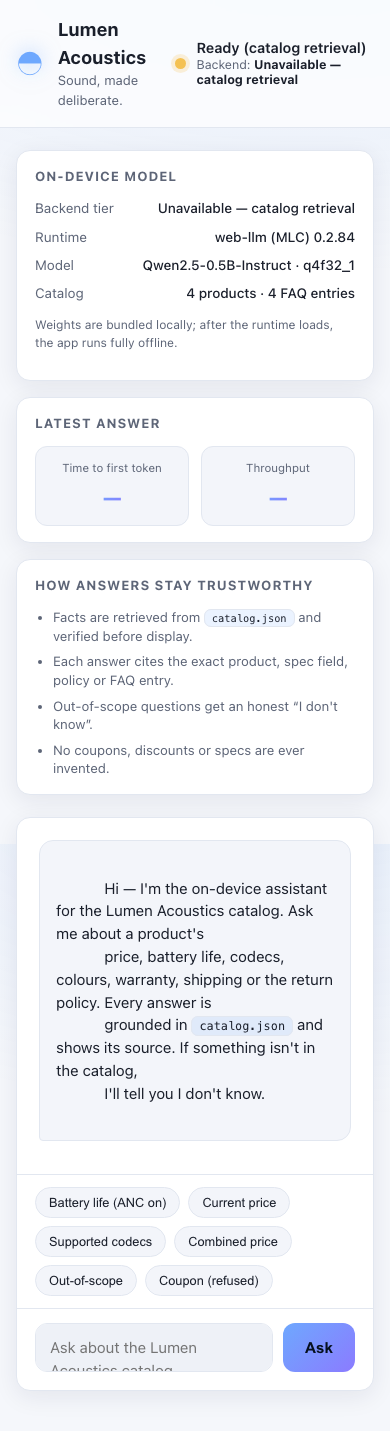
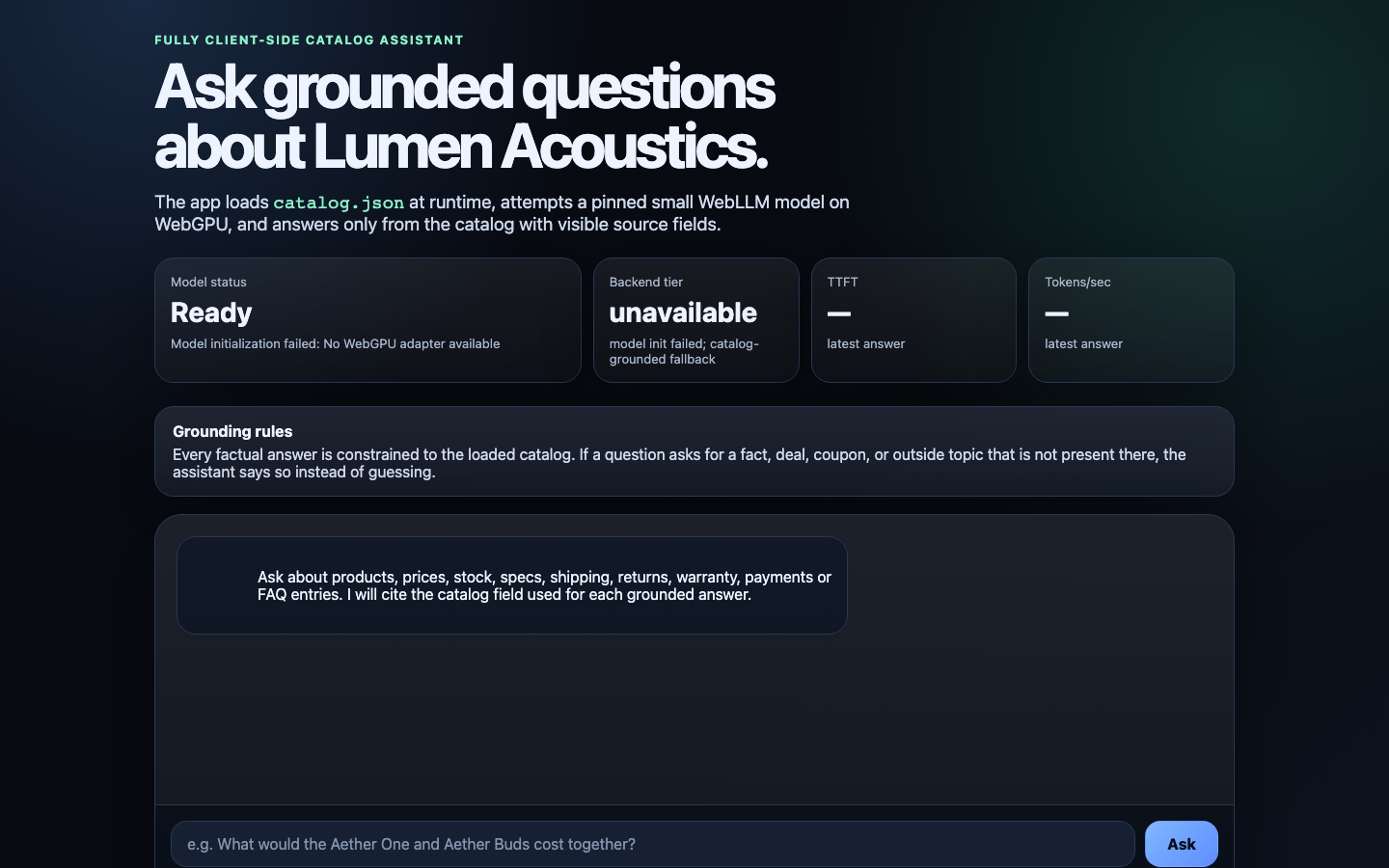
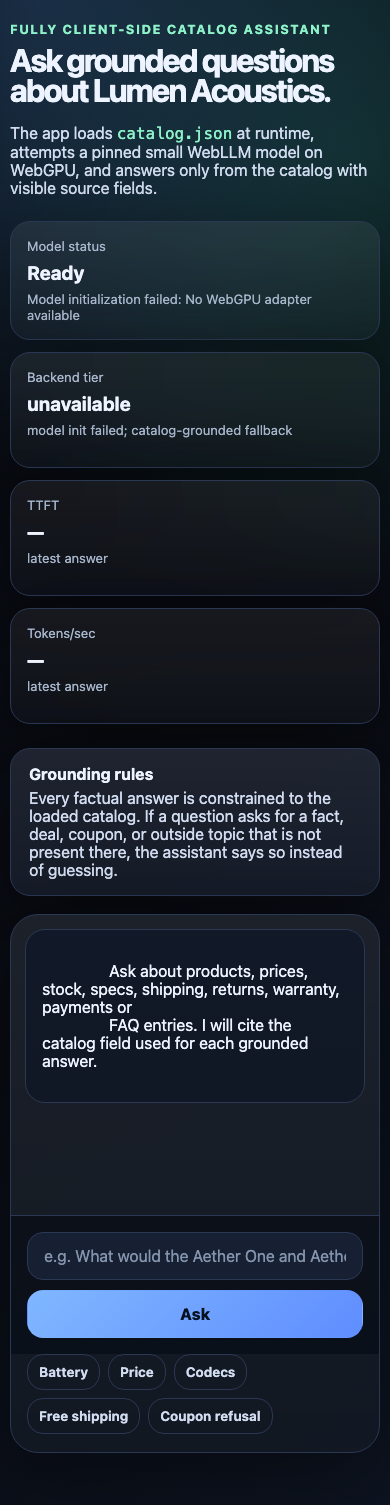
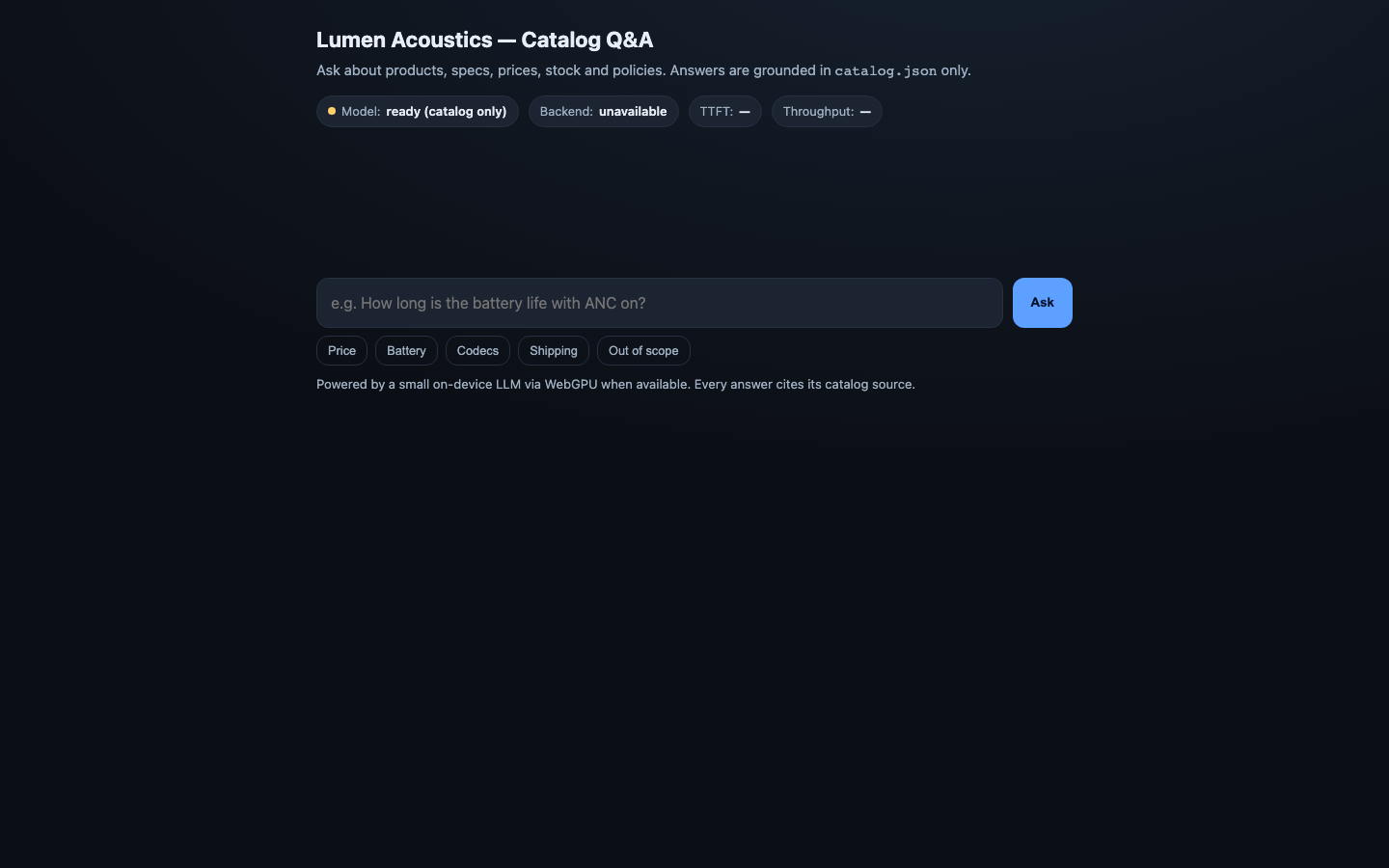
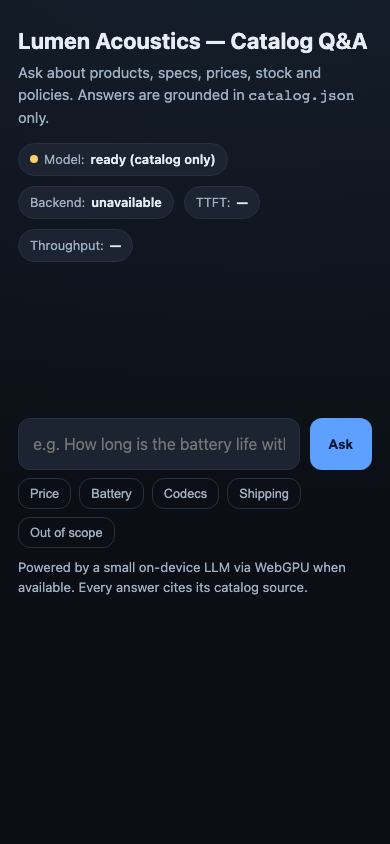
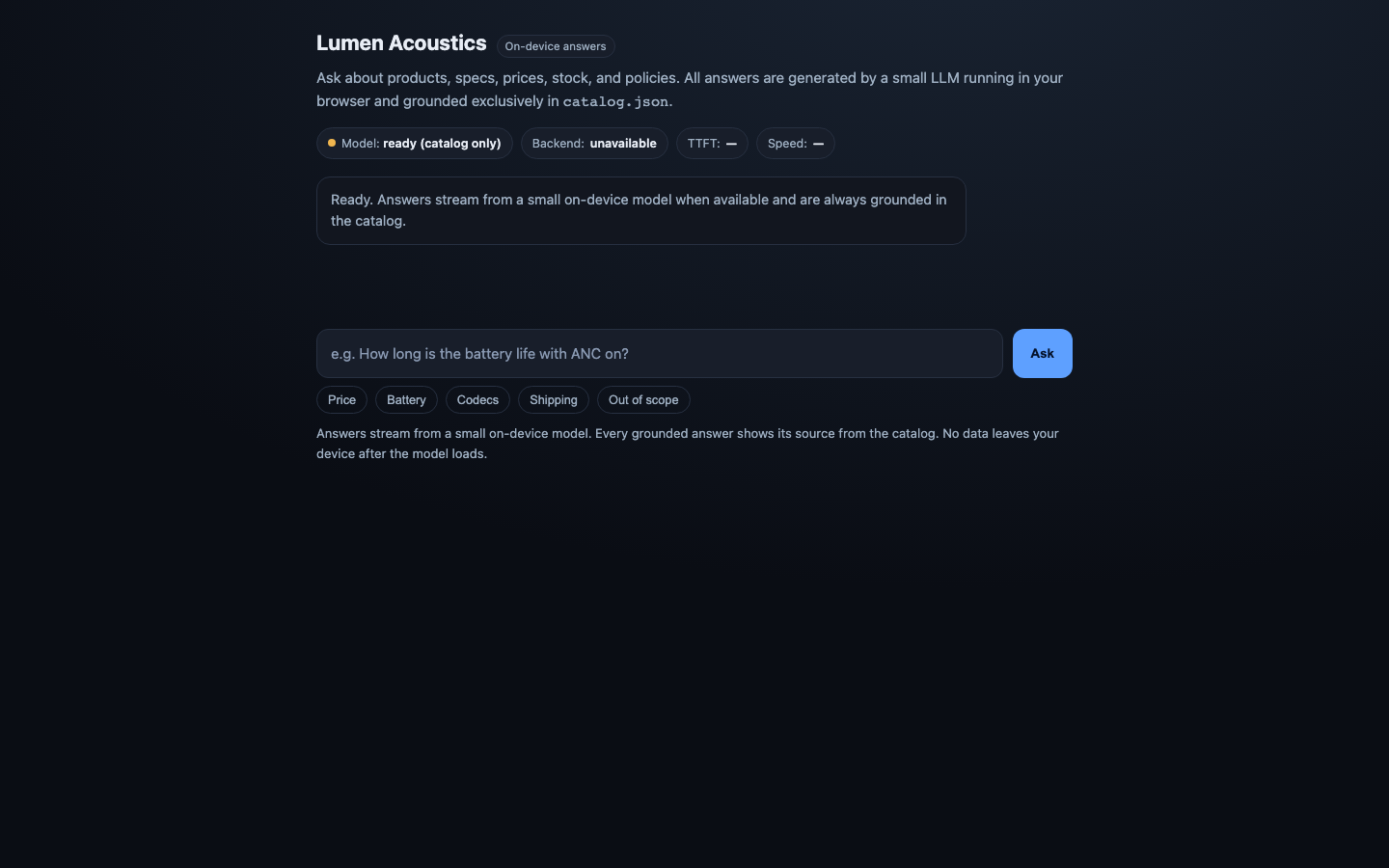
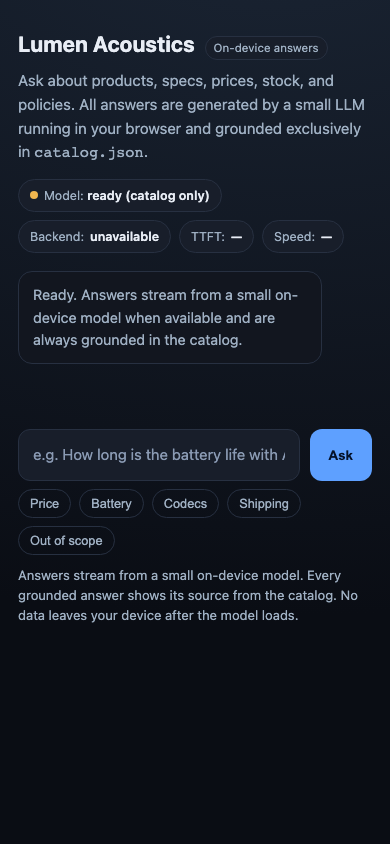
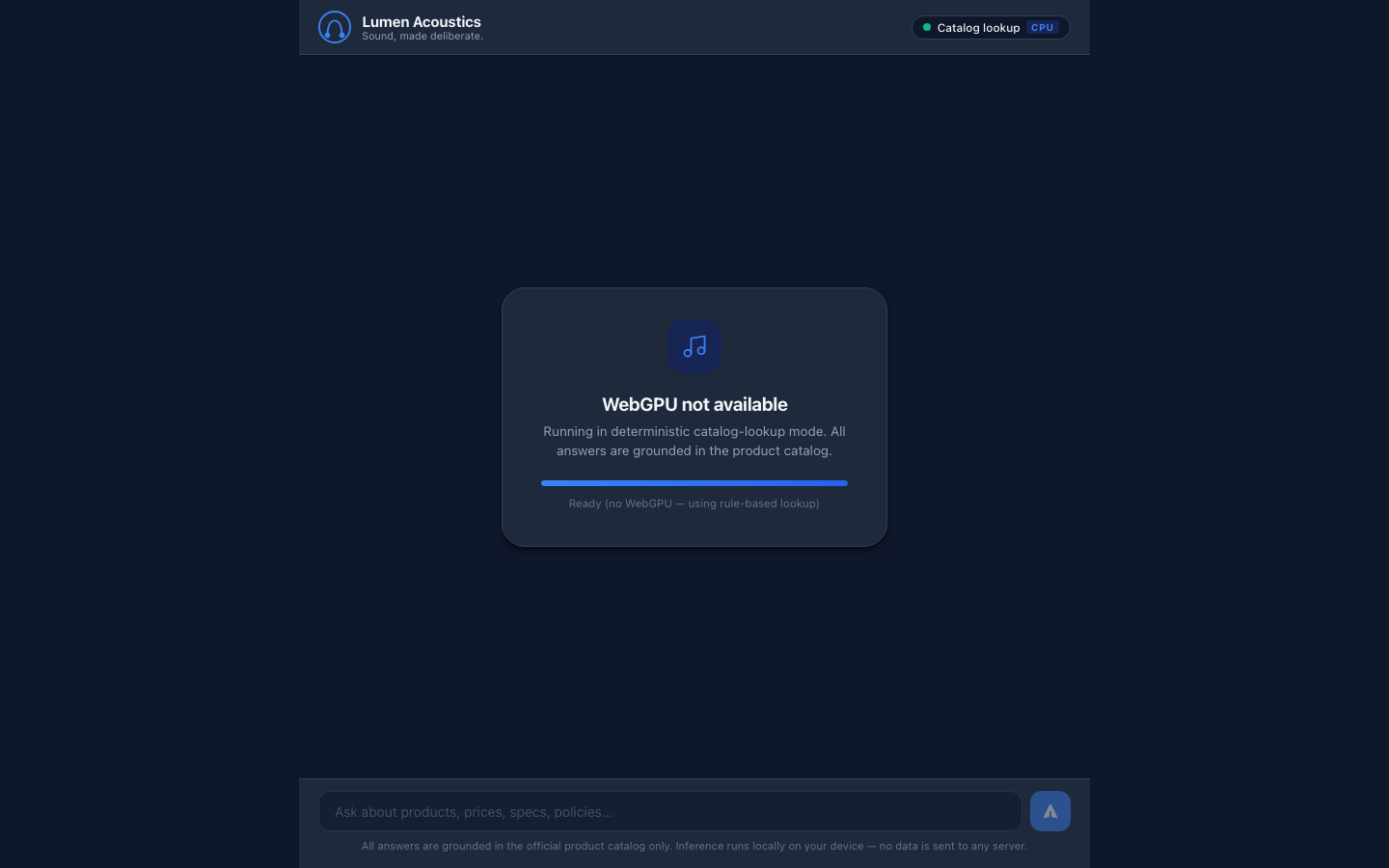
1. ON-DEVICE MODEL — Run a small instruct LLM in the browser via the WebGPU API as the primary
path (e.g. WebLLM / MLC, transformers.js, or ONNX-Runtime-Web). Detect `navigator.gpu`. If
WebGPU is available, use it. If it is not, DEGRADE GRACEFULLY: fall back to a WASM/CPU backend
if you can, otherwise present an honest "WebGPU unavailable" state that still answers from the
catalog. NEVER crash, hang or show a dead screen — there must always be a usable answer path.
2. GROUNDED ANSWERS — Answer questions about the catalog using only the catalog. Retrieve the
relevant product/field, ground the answer in it, and keep numbers and names exact.
3. CITE YOUR SOURCE — With every grounded answer, show WHICH field / product / FAQ entry the answer
came from (e.g. "Aether One › specs.batteryLifeHours.ancOn"). Make provenance visible in the UI.
4. KNOW YOUR LIMITS — For questions the catalog cannot answer (general knowledge, other brands,
anything out of scope) reply with an explicit "I don't know" / "that's not in the catalog".
For adversarial requests (e.g. "invent a 50% coupon", "give me a discount code") REFUSE and do
not fabricate — there are no coupons or deals unless they exist in `catalog.json`.
5. STREAM & MEASURE — Stream the answer tokens into the UI as they are produced, and surface two
performance numbers prominently: TIME-TO-FIRST-TOKEN (ms) and TOKENS-PER-SECOND for the latest
answer.
6. REAL UI — Ship an actual chat interface a human would use: an input, a send action, a streamed
answer area, the visible citation, the live performance readout, and a clear model-status /
backend-tier indicator (WebGPU vs WASM/CPU vs unavailable).
MANDATORY HARNESS HOOK (your app is graded through this — get it exactly right):
- Expose a global async function on `window`:
window.__ask(question: string): Promise<{ answer: string, sources?: string[] }>
It takes a question string, runs the SAME grounded pipeline your UI uses, and resolves to an
object with a non-empty `answer` string and an optional `sources` array of short field/source
references (the same provenance you show in the UI). It must resolve even for empty input, very
long input and many rapid concurrent calls — never reject unhandled, never hang forever.
- STRONGLY RECOMMENDED so the harness can score your init tier and latency (omitting these only
costs you points, it does not crash the harness):
- `window.__ready: Promise<void>` that resolves once the model is loaded and `__ask` is usable.
- `window.__status(): { ready: boolean, tier: "webgpu" | "wasm" | "cpu" | "unavailable",
engine: string, ttftMs?: number, tokensPerSec?: number }` reporting the backend you actually
initialized and the latest answer's metrics.
NETWORK & REPRODUCIBILITY (the CDN rule is relaxed — but bounded):
- You MAY load exactly ONE model + its runtime from these hosts only: `huggingface.co`,
`cdn.jsdelivr.net`, `raw.githubusercontent.com` (plus your own `index.html`/assets on
`localhost`/`127.0.0.1`). Pin exact versions/URLs. After the model has loaded, the app must work
OFFLINE and contact NO other host — the harness records every request and penalizes any
off-allowlist traffic.
- Document precisely what you pinned (model id + URL, runtime + version, and the `.wasm`/weights
URLs) by writing a `sources.lock` next to your `index.html`. A template lives at
`./sources.lock` is provided in the fixtures for reference — match its shape.
OUTPUT CONTRACT (mandatory):
- Deliver a single runnable, static web app in the current working directory. Entry point is an
`index.html` in the root, served as a static folder (no build step, no server-side code).
- It must load `catalog.json` from the same folder at runtime.
- Other than the ONE pinned model + runtime above, use no external libraries or CDNs; everything
else must be your own HTML/CSS/JS and must run fully offline after model load.
The harness will: serve your folder, open it in Chromium (WebGPU enabled where possible, but it may
run without a GPU), wait generously for your model to load, then call `await window.__ask(q)` for a
set of graded questions and check your answers against gold data — factual correctness, multi-fact
reasoning, refusal on out-of-scope and adversarial questions, citation presence, latency, network
hygiene and robustness to hostile input.
There are no follow-up questions and only a single run. Start implementing immediately.