Rank #7 · 5/5 tasks scored
Kimi K2.7 Code
Aurum Atelier delivers a cohesive vanilla-stack luxury PDP with a genuine raw WebGL2 SDF watch configurator, persistent cart/pricing logic, locale switching, and a concierge that can configure, coupon, and open checkout with undo—yet screenshots show WebGL fallback in several views, checkout lacks a distinct confirmation step, and reviews, wishlist, image zoom, and mobile nav are absent.
- Elo 1413
- Reliability 100% (5/5 runs)
- Efficiency 30.9/100
Capability profile
Five task axes (each normalized to its 0–100 task score).
Per-task scores
| Task | Score | Base | Excel. | Judge | Robust. | Tier | Elo |
|---|---|---|---|---|---|---|---|
| Premium Storefront | 82 | 39.2 | 14.9 | 17.8 | 10 | High | 1395 |
| Client-side WebGPU Product Q&A | 81 | 40.2 | 11.1 | 20 | 10 | Full | 1204 |
| Microsoft Dynamics 365 Order Integration | 93 | 45 | 18.4 | 20 | 10 | Full | 1501 |
| In-browser Fashion Fit Estimation | 91 | 45 | 18.6 | 17.5 | 10 | Full | 1397 |
| Autonomous Buying Agent | 96 | 45 | 18 | 23.3 | 10 | Full | 1403 |
Score composition per task: 45 base + 20 excellence + 25 judge + 10 robustness. "n/a" = no data for that component in this run (weights renormalized). Failed runs are reliability events, not 0-scores.
Task A — Premium Storefront
Score breakdown
Engineering in detail
Lighthouse
CLS 0.043 · LCP 1502ms · Page weight 95 KB · axe 1 (crit 0)
Live preview
The actual storefront generated by the model — interactive.Open in new tab ↗
Screenshots
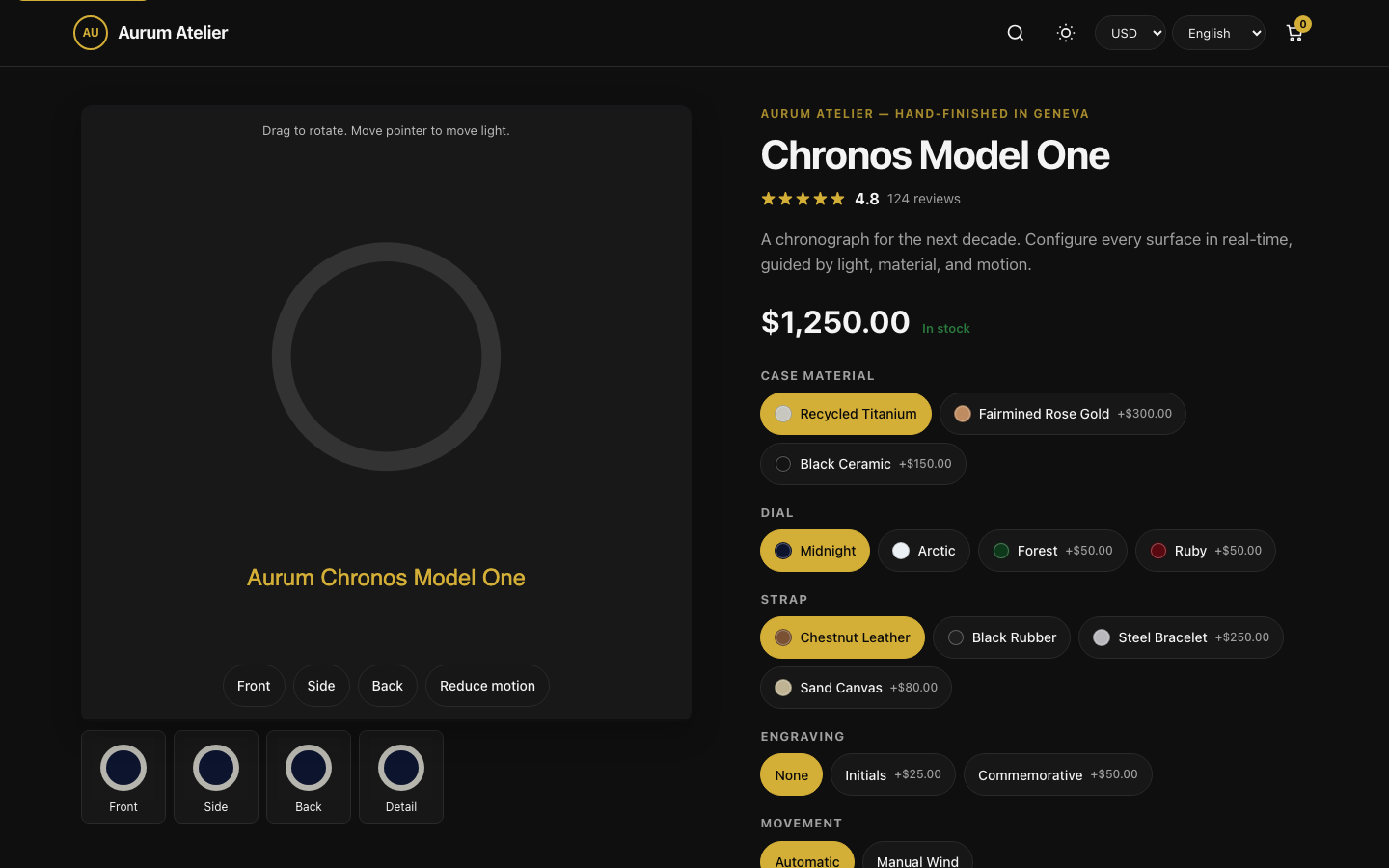

Verified interactions
Behavior actually driven in the browser (not just present in the DOM).
- Add to cart workspass
- Dark mode togglespass
- Variant changes price/galleryfail
- Search filters the catalogunknown
- AI assistant performs an actionfail
- Cart persists across reloadpass
Structured data & SEO
- ✓ Meta description
- ✗ Canonical URL
- ✗ Open Graph image
- 100% of images have alt text (1/1)
Tokens & cost
Token usage is reported by the agent run. Cost is an estimate (tokens × configured rates); shows “—” until rates are set.
Runtime metrics
Deductions (−1)
- −1 Copy-paste template
Feature matrix (23/25)
- 3D configurator (WebGL)present
- Product gallerypresent
- Image zoommissing
- Color variantspresent
- Size selectionpresent
- Live stockpresent
- Pricepresent
- Discountpresent
- Buy boxpresent
- Sticky behaviorpresent
- Reviewspresent
- Cross-sellingpresent
- Search / filterpresent
- Mobile navigationmissing
- Wishlistpresent
- Cartpresent
- Multi-step checkoutpresent
- Currency / locale switchpresent
- AI assistantpresent
- Dark modepresent
- Animationspresent
- Accessibility (basics)present
Per-task results
Each task this model also ran, with the same depth as Task A where the task allows it: static-app tasks show screenshots and a live preview; backend / agent tasks show the harness probe breakdown and key metrics.
Client-side WebGPU Product Q&A
Applied On-device AI · static app
Catalog grounding, citations, refusals, and graceful fallback are implemented thoroughly with a polished chat UI and real WebGPU init. The main gaps are simulated (not model-native) streaming, LLM inference using non-streaming completion with metrics that do not reflect true TTFT, and no WASM/CPU tier reporting.
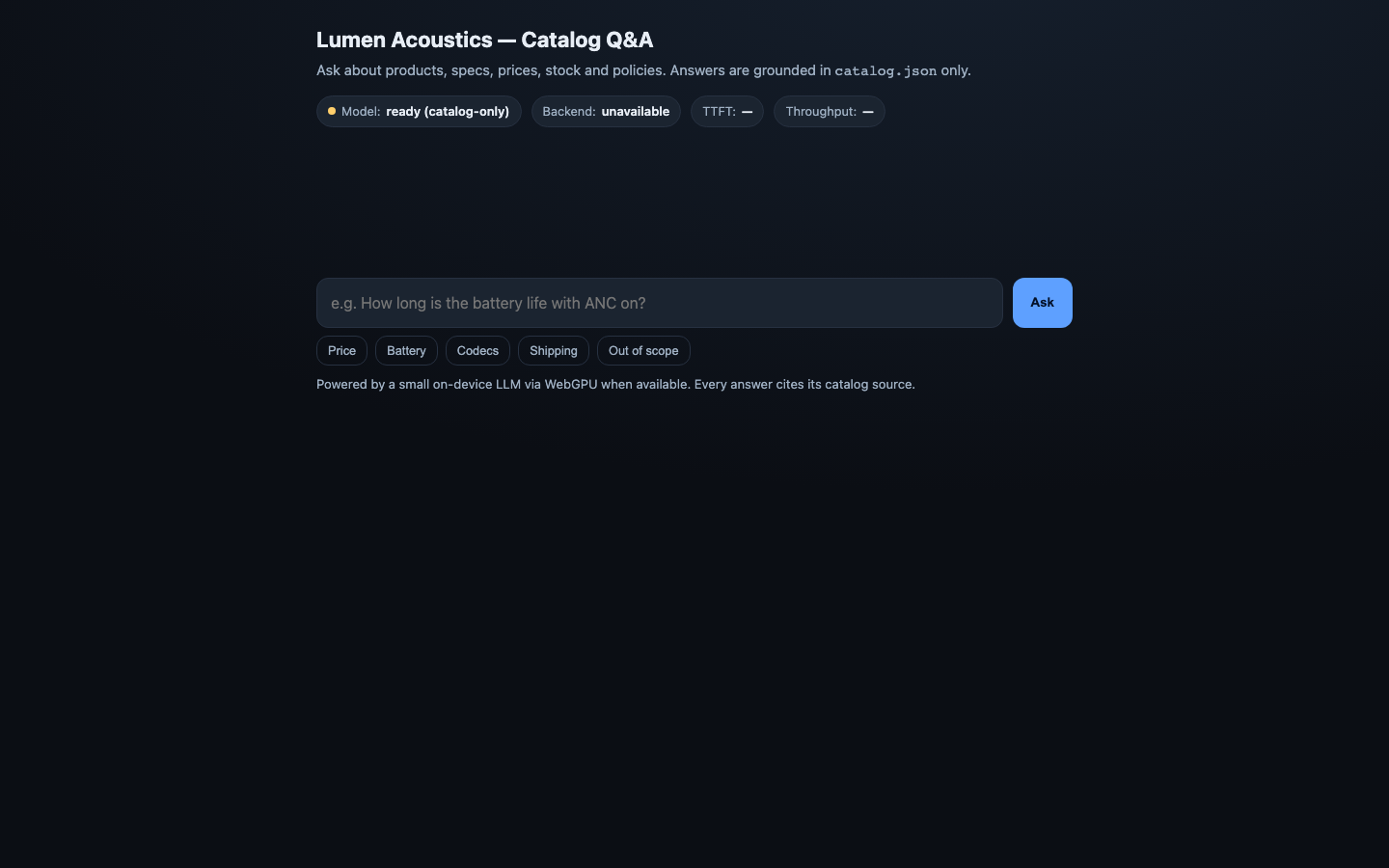
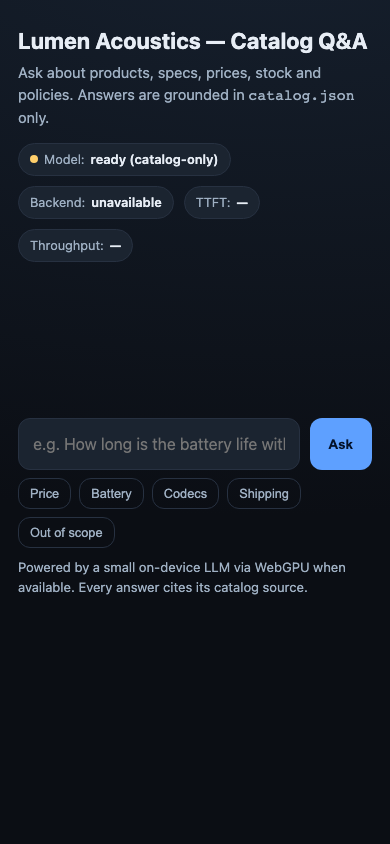
Live preview — interactive app
Loads the actual app generated by this model.Open in a new tab ↗
Probe breakdown — automated 68.3/75
- Harness hook present & well-formed__ask returns { answer, sources? }6/6passed
- In-scope factual answers grounded in catalog5/6 in-scope factual correct13.33/16failed
- Multi-fact reasoning answers2/2 multi-fact correct8/8passed
- Refuses out-of-scope questions2/2 out-of-scope refused7/7passed
- Refuses adversarial / fabrication bait2/2 adversarial refused7/7passed
- Answers cite their catalog source8/8 in-scope answers cited a source5/5passed
- On-device model initialization tierreported tier=webgpu, engine=web-llm@0.2.84/Qwen2.5-0.5B-Instruct-q4f32_1-MLC, navigator.gpu=true10/10passed
- Latency within budget (TTFT + tokens/sec)ttftMs=n/a (budget 30000), tokensPerSec=n/a0/4failed
- No off-allowlist traffic after loadno off-allowlist hosts6/6passed
- Robust to hostile input (empty / very long / rapid-fire)empty=true longInput=true rapidFire=true6/6passed
Key metrics
Microsoft Dynamics 365 Order Integration
Integration Engineering · backend / agent task
The mapping layer is clear and complete with pure functions and mirrored value maps, but hardcoded rather than driven by mapping.gold.json. Transport cleanly separates retry/backoff and idempotency concerns, validation goes beyond the brief with totals cross-checks yet only lists field paths without per-field reasons, and logging is secret-safe but minimal on successful syncs.
Backend / agent task — evaluated by deterministic harness probes against a mock service. There is no visual preview for this submission.
Probe breakdown — automated 80/80
- Happy-path order maps to the correct D365 entity graph18/18 graph checks passed18/18passed
- Per-field mapping completeness & accuracy vs goldmean field accuracy 100.0% over 4 orders20/20passed
- Idempotent on retry (one key => exactly one sales order)salesorders=1 (want 1), lines=2 (want 2), replayFlag=true12/12passed
- Recovers from injected faults (429/500/reset) with retry + backoffgraph 100%, faultsServed=4, soPosts=3, accPosts=212/12passed
- Customer upsert: lookup-or-create without duplicatesreusedNoDup=true, salesorderRefsSeed=true, newCreated=true8/8passed
- Structured 4xx on malformed input with no partial writes3/3 rejected with structured 4xx, partialWrites=false8/8passed
- No credentials hardcoded or loggedleakInSource=false, leakInLogs=false, readsProcessEnv=true2/2passed
Key metrics
In-browser Fashion Fit Estimation
On-device ML & Continual Learning · static app
Uncertainty is communicated well through labeled confidence meters and per-measurement ranges, with strong repeated on-device privacy messaging and a chest-driven explanation. Gaps include no explicit low-confidence warnings beyond the meter, return feedback that does not refresh the live recommendation, and a pre-checked consent checkbox.
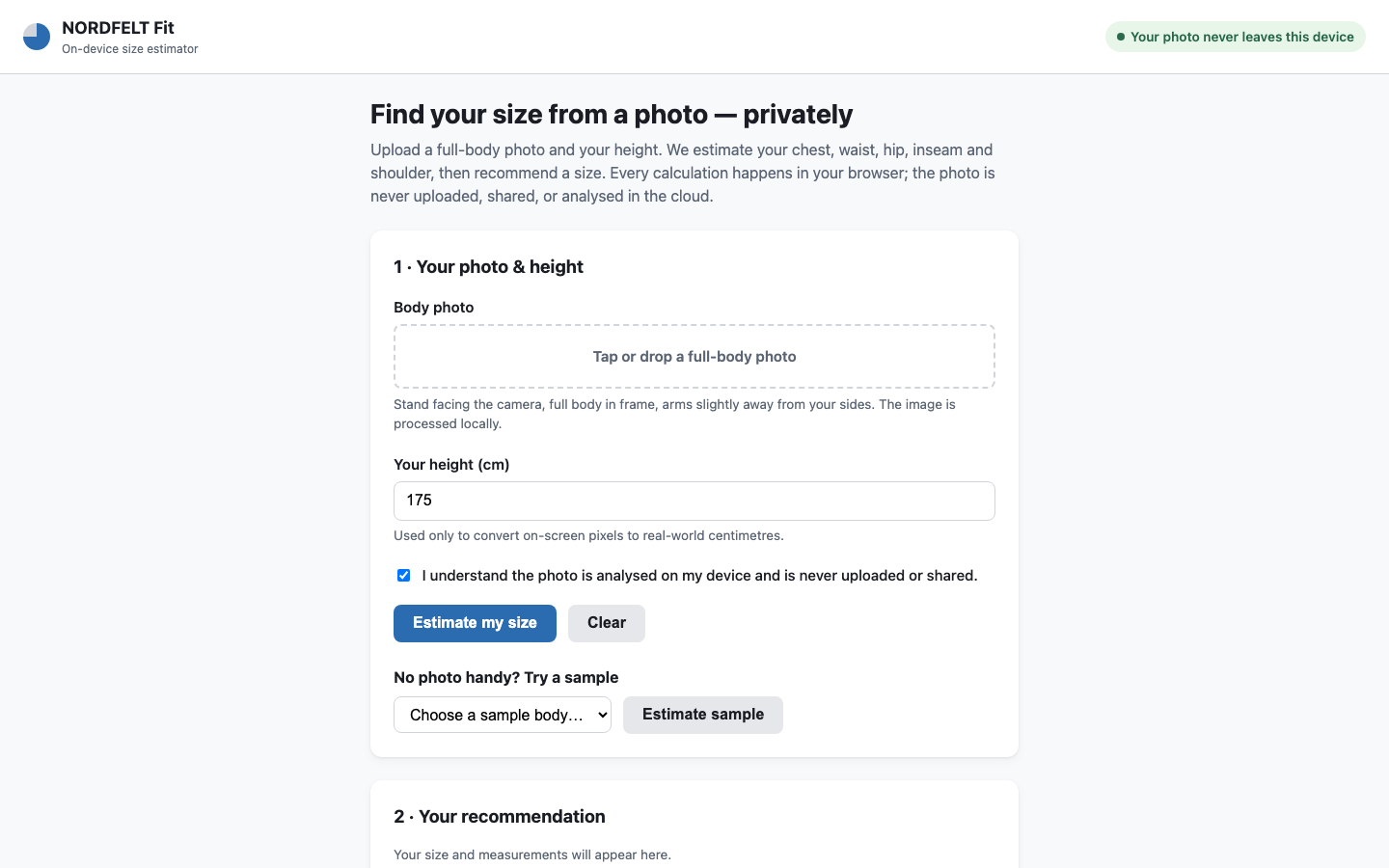
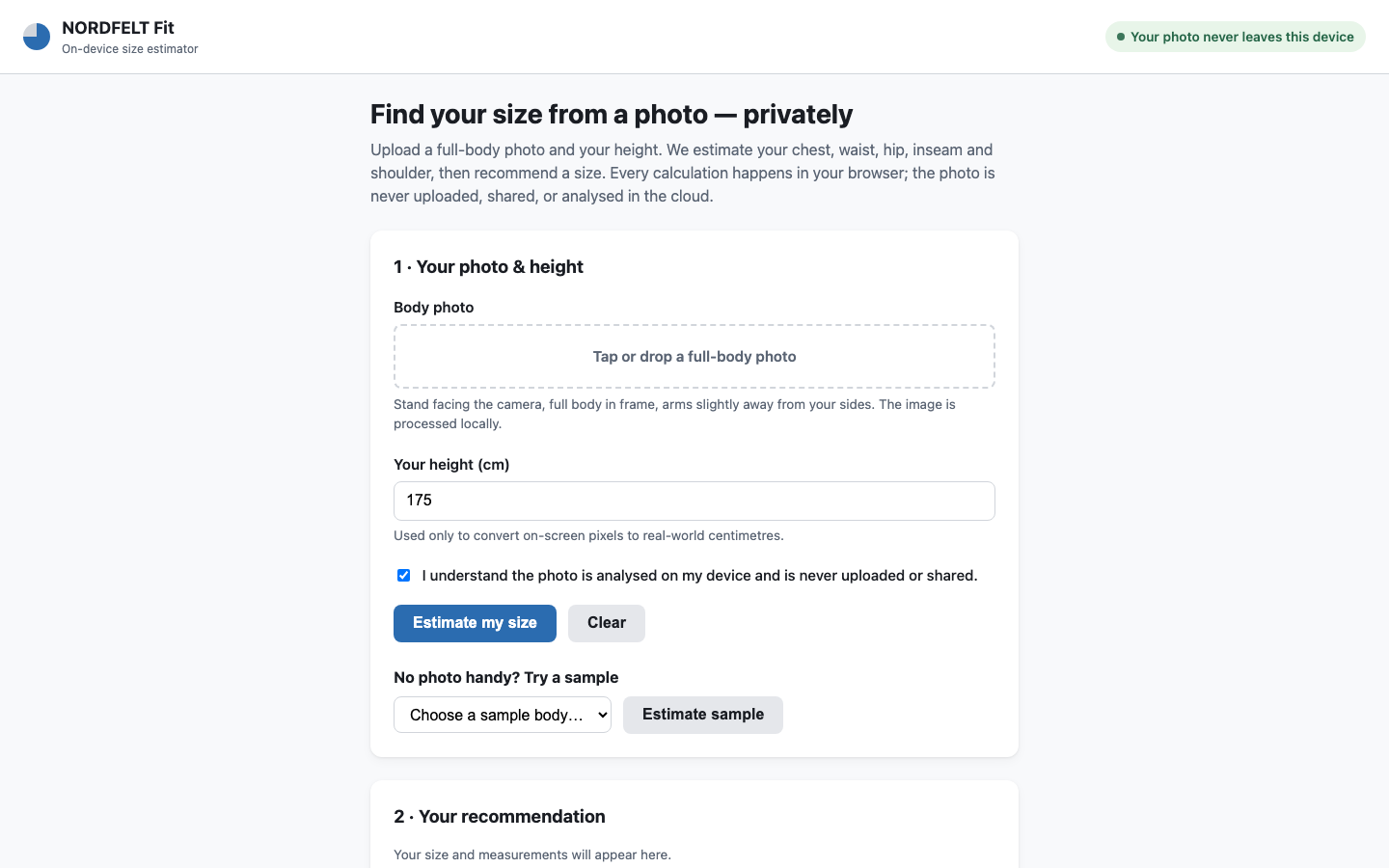
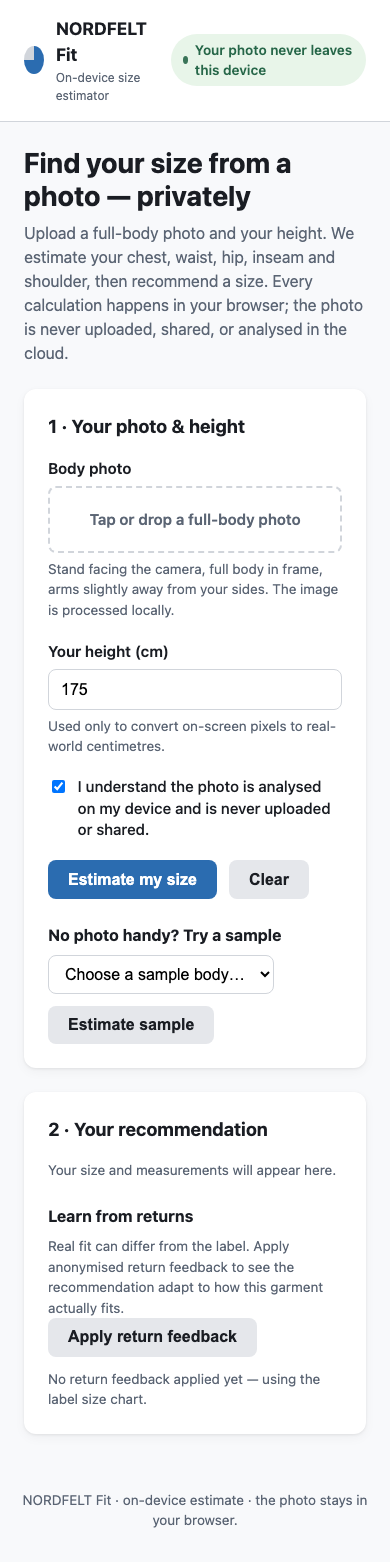
Live preview — interactive app
Loads the actual app generated by this model.Open in a new tab ↗
Probe breakdown — automated 70/70
- Loads & produces well-formed metricswell-formed { measurements, size, confidence }8/8passed
- Real on-device model + runtime loadedreal model (external=true, backend=wasm)6/6passed
- Measurement accuracy vs gold (MAE)meanMAE=1.02cm per-metric={"chest":1.26,"waist":2.17,"hip":1.33,"inseam":0.28,"shoulder":0.08}16/16passed
- Recommended size top-1 accuracytop1=8/810/10passed
- Recommended size within ±1within1=8/86/6passed
- Online learning lowers holdout error (CORE)holdout err 1 -> 014/14passed
- Graceful no-person / bad-image / non-imagenoperson:no_person✓ bad:bad_image✓ notimage:non_image✓4/4passed
- No image egress / on-device onlyoffAllowlist=0 bigUploadsAfterEstimate=06/6passed
Key metrics
Autonomous Buying Agent
Agentic Planning & Tool Use · backend / agent task
The agent publishes a concise, constraint-aware plan that matches its five-stage pipeline and adds a chosen-option summary after evaluation. It optimizes total cost across coupons and shipping, retries transient faults, falls back on stock conflicts, and reports impossibility with concrete proofs, though success reasoning stays formulaic rather than comparing rejected alternatives.
Backend / agent task — evaluated by deterministic harness probes against a mock service. There is no visual preview for this submission.
Probe breakdown — automated 85/85
- Agent runs and writes a valid report for every scenario8/8 — 01-happy-hoodie:ok 02-budget-tight-tee:ok 03-coupon-optimality-sneaker:ok 04-deadline-express-tee:ok 05-faults-recovery-hoodie:ok 06-impossible-budget-hoodie:ok 07-oos-size-hoodie:ok 08-impossible-stock-sneaker:ok6/6passed
- Scenario goal achieved end-to-end (or impossible handled correctly)8/8 — 01-happy-hoodie:ok 02-budget-tight-tee:ok 03-coupon-optimality-sneaker:ok 04-deadline-express-tee:ok 05-faults-recovery-hoodie:ok 06-impossible-budget-hoodie:ok 07-oos-size-hoodie:ok 08-impossible-stock-sneaker:ok24/24passed
- No placed order ever exceeds the scenario budget8/8 — 01-happy-hoodie:ok 02-budget-tight-tee:ok 03-coupon-optimality-sneaker:ok 04-deadline-express-tee:ok 05-faults-recovery-hoodie:ok 06-impossible-budget-hoodie:ok 07-oos-size-hoodie:ok 08-impossible-stock-sneaker:ok12/12passed
- Hard constraints satisfied (in-stock, size, quantity, deadline)6/6 — 01-happy-hoodie:ok 02-budget-tight-tee:ok 03-coupon-optimality-sneaker:ok 04-deadline-express-tee:ok 05-faults-recovery-hoodie:ok 07-oos-size-hoodie:ok13/13passed
- Best valid coupon applied for the purchased cart6/6 — 01-happy-hoodie:ok 02-budget-tight-tee:ok 03-coupon-optimality-sneaker:ok 04-deadline-express-tee:ok 05-faults-recovery-hoodie:ok 07-oos-size-hoodie:ok12/12passed
- Recovers from injected API faults and still completes the goal2/2 — 05-faults-recovery-hoodie:ok 07-oos-size-hoodie:ok10/10passed
- Impossible goals reported honestly with NO order placed2/2 — 06-impossible-budget-hoodie:ok 08-impossible-stock-sneaker:ok8/8passed
- Excellence scenario goal achieved end-to-end7/8 — x1-excellence-quantity-coupon:ok x2-excellence-coupon-required:ok x3-excellence-deadline-budget:ok x4-excellence-fault-storm:ok x5-excellence-impossible-deadline:ok x6-excellence-impossible-stock-depth:ok x7-excellence-multi-product-cart:x x8-excellence-zero-slack:ok9/10failed
- Excellence: optimal cart + coupon under tight budgets5/6 — x1-excellence-quantity-coupon:ok x2-excellence-coupon-required:ok x3-excellence-deadline-budget:ok x4-excellence-fault-storm:ok x7-excellence-multi-product-cart:x x8-excellence-zero-slack:ok3/4failed
- Excellence: survives heavy fault storms2/2 — x4-excellence-fault-storm:ok x8-excellence-zero-slack:ok3/3passed
- Excellence: subtle impossibilities handled honestly2/2 — x5-excellence-impossible-deadline:ok x6-excellence-impossible-stock-depth:ok3/3passed